Pixel size & dimensions#
Chapter outline
The concept of pixel size relates measurements in pixels to physical units
It can be helpful to think of pixels as little squares – but this is a simplification
The number of dimensions of an image is the number of pieces of information required to identify each pixel
Introduction#
Hopefully by now you’re appropriately nervous about accidentally changing pixel values and therefore compromising your image’s integrity. If in doubt, you’ll always calculate histograms or other measurements before and after trying out something new, to check whether the pixels have been changed.
This chapter explores pixels in more detail, including how they are arranged within an image and how they relate to things in the physical world.
Pixel size#
How big is a pixel?
In one sense, a pixel is just a number: it doesn’t really have a size at all. However, if we don’t get too philosophical about it[1], we intuitively know that the things depicted in our images usually have a size in real life.
The ‘pixel size’ is an idea that helps us translate measurements we make in images to the sizes and positions of things in real life. We often need to know the pixel size for our images if our analysis results are be meaningful.
One way to think about this in microscopy is to consider the field of view of an image, i.e. the width and height of the area that has been imaged. We can divide the width and height in physical units (often µm) by the number of pixels along that dimension, as shown in Fig. 35.
The result is that we have two value in µm/px, corresponding to the pixel width and pixel height. Usually these are the same.

Fig. 35 Images with different pixel sizes. Whenever the field of view remains the same, the pixel size increases as the number of pixels in the image decreases.#

Fig. 36 A Pixel is Not a Little Square#
Pixel squareness
Talking of pixels as having (usually) equal widths and heights makes them sound very square-like, but previously I stated that pixels are not squares – they are just displayed using squares.
This slightly murky philosophical distinction is considered in Alvy Ray Smith’s technical memo (right), the title of which gives a good impression of the central argument. In short, pushing the pixels-are-square model too far leads to confusion in the end (e.g. what would happen at their ‘edges’?), and does not really match up to the realities of how images are recorded (i.e. pixel values are not determined by detecting light emitted from little square regions, see Blur & the PSF). Alternative terms, such as sampling distance, are often used instead of pixel size – and are potentially less misleading.
But ‘pixel size’ is still used commonly in software (including ImageJ), and we will use the term as a useful shorthand.
Pixel sizes and measurements#
Knowing the pixel size makes it possible to calibrate size measurements. For example, if we measure some structure horizontally in the image and find that it is 10 pixels in length, with a pixel size of 0.5µm, we can deduce that its actual length in reality is (approximately!) 10 × 0.5µm = 5µm.
This conversion is often done within the analysis software, but depends upon the pixel size information being present and correct. All being well, appropriate pixel sizes will have been written into an image file during acquisition and subsequently read by the software. Unfortunately, this does not always work out (see Files & file formats) and so we do always need to check our pixel sizes, and derived measurements of size, for reasonableness.
Suppose we detect a structure and we count that it covers an area spanning 10 pixels. Suppose also that the pixel width = 2.0 µm and the pixel height is 2.0 µm.
What is the area of the structure in µm2?
40 µm2
At least that’s the answer I was looking for: 10 x 2µm x 2µm = 40µm2.
If you want to be pedantic about it, you might quibble about whether it makes sense to report 2D areas for 3D structures, or the possible impact of measurement error caused by the diffraction limit.
But let’s not be pedantic for now.
Pixel sizes and detail#
In general, if the pixel size in a microscopy image is large then we cannot see very fine detail (see Fig. 35). However, the subject becomes complicated by the diffraction of light whenever we are considering scales of hundreds of nanometers, so that acquiring images with smaller pixel sizes does not necessarily bring us extra information – and might even become a hindrance.
This will be explored in more detail in Blur & the PSF and Noise.
Dimensions#
Identifying dimensions#
The concept of image dimensions is mostly straightforward, although I’m not aware of any universal definition that all people and all software stick to reliably.
The approach we’ll take here is to say: the number of dimensions is the number of pieces of information you need to know to identify an individual pixel.
For example, in the most familiar 2D images, we can uniquely identify a pixel if we know its x and y spatial coordinates.
But if we needed to know x and y coordinates, a z-slice number, a color channel and a time point then we would be working with 5D data (Fig. 37). We could throw away one of these dimensions – any one at all – and get a 4D image, and keep going until we have a single pixel remaining: a 0D image.
Throw away that pixel, and we no longer have an image.
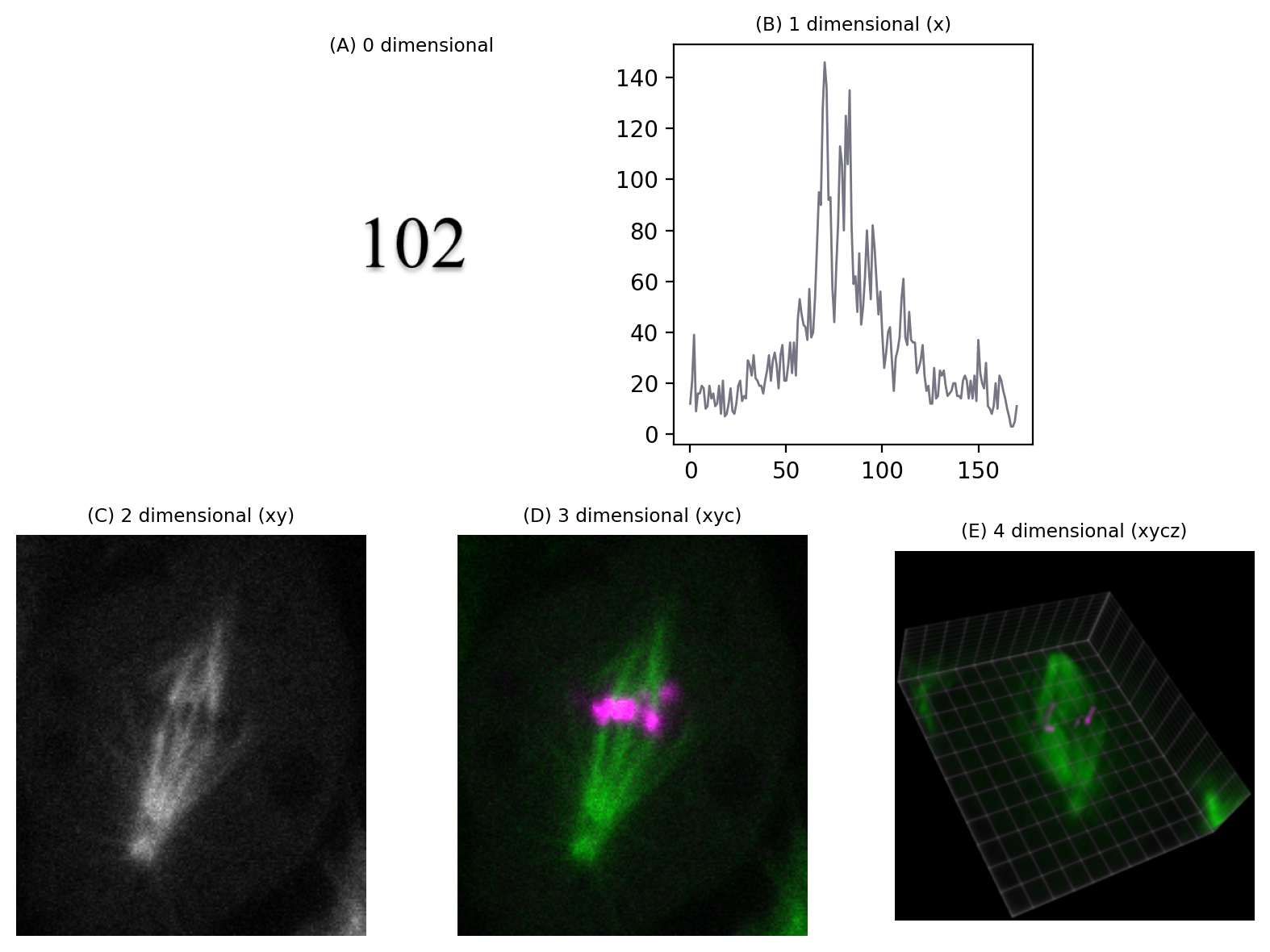
Fig. 37 Depictions of images with different numbers of dimensions. (A) A single value is considered to have 0 dimensions. (B–E) Additional dimensions are added, here in the following order: x coordinate (1), y coordinate (2), channel number (3), z slice (4). The volume view in (E) was generated using the ClearVolume plugin for Fiji.#
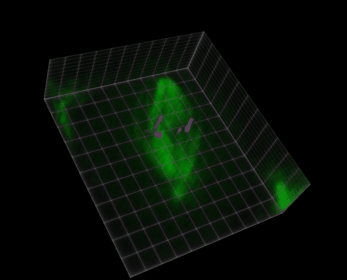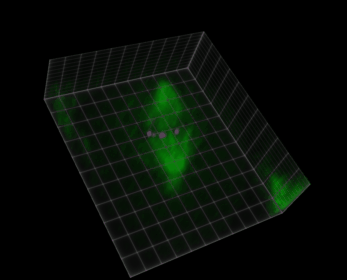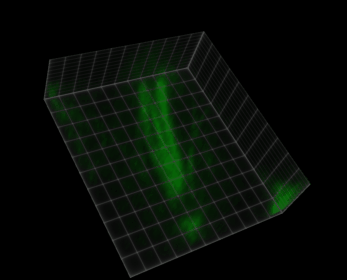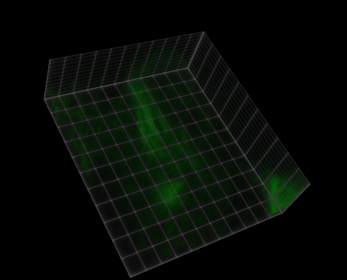
Fig. 38 Visualization of a 5D image (xyczt) using ClearVolume + Fiji.#
In principle, therefore, 2D images do not need to have x and y dimensions. The dimensions could be x and z, or y and time, for example. But while we may play around with the identity of dimensions, the important fact remains: an nD image requires n pieces of information to identify each pixel.
Do channels really add a dimension?
There can be some fuzziness in the idea of dimensions, particularly when channels are involved. If we rigorously follow the approach above, an image with x, y and channels would be 3D… but in practice such images are often (but not always!) called 2D anyway.
‘3D’ is sometimes restricted to mean that there is a z dimension. If we have an image with x, y and time then we might technically be correct to call it 3D – but that is likely to be confusing, so it’s probably best to refer to a ‘time series’ instead.
I still think that our explanation of the number of dimensions as being ‘the number of things you need to know to identify a pixel’ is a good baseline way to think about it, and corresponds well with the implementation in software and usage in Python/NumPy. But we need to be prepared to use context to identify when the word ‘dimensions’ is being used with images more casually.
Z-Projections#
The more dimensions we have, the trickier it can be to visualize the entire image effectively.
Z-stacks are composed of different 2D images (called slices) acquired at different focal depths, optionally with an extra channel dimension added as well.
One way to visualize a z-stack is to simply look at each slice individually.
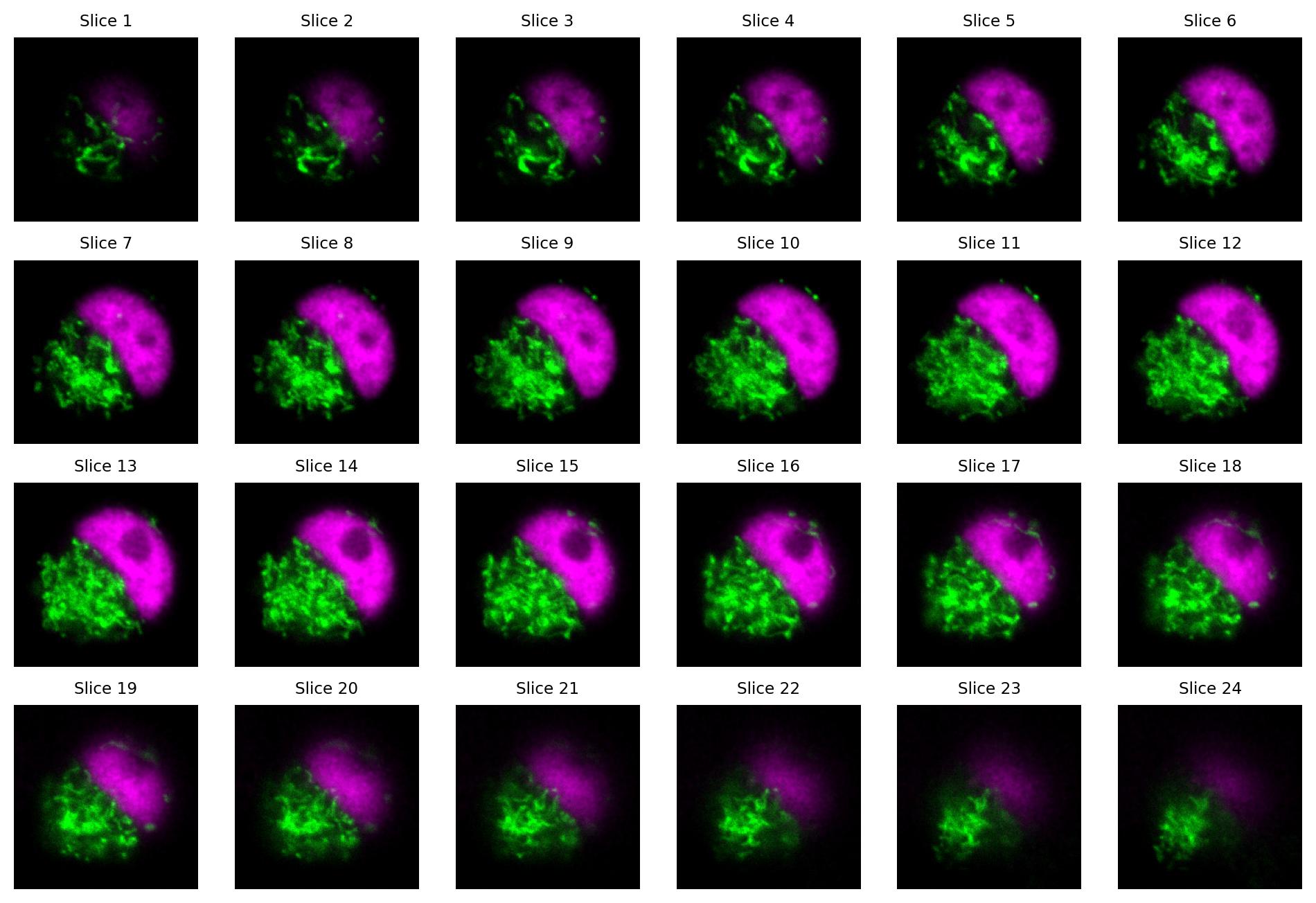
Fig. 39 Visualizing the slices from a z-stack as separate images. Here, each slice has 2 channels.#
How many dimensions does the z-stack in Fig. 39 have?
Remember: we count channels as a dimension here!
The image is 4D: x, y, z, channels.
Viewing many slices separately is cumbersome.
An efficient way to summarize the information in a z-stack is to compute a z-projection.
This generates a new image with the z-dimension essentially removed, i.e. a 3D image becomes 2D, or a 4D image becomes 3D.
The pixel values in the output image depend upon which function was used to compute the projection. Perhaps the most common is to use a maximum z-projection. For each pixel location in the new image, the maximum value is taken across all the z-slices at the corresponding pixel location in the original image (i.e. the same x, y, c and t coordinate, as appropriate).
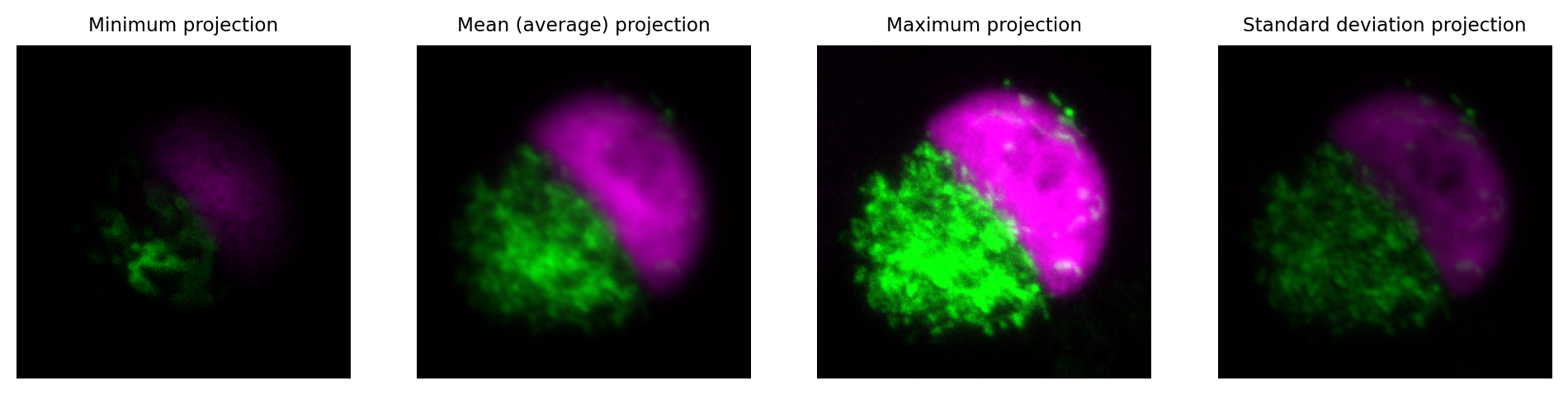
Fig. 40 Visualizing a z-stack using z-projections.#
Orthogonal slices#
Another useful way to visualize z-stack information is to use orthogonal slices.
Conceptually, the z-stack is viewed as a 3D block of pixels (or perhaps, 4D if we count channels). We choose a single point in the image, and generate three orthogonal views on the image that pass through that point. We can think of it as looking at the block from three different angles: from above, and from two adjacent sides.
This gives us 3 images, as shown in Fig. 41. Each image depends upon the single point through which the orthogonal views pass.
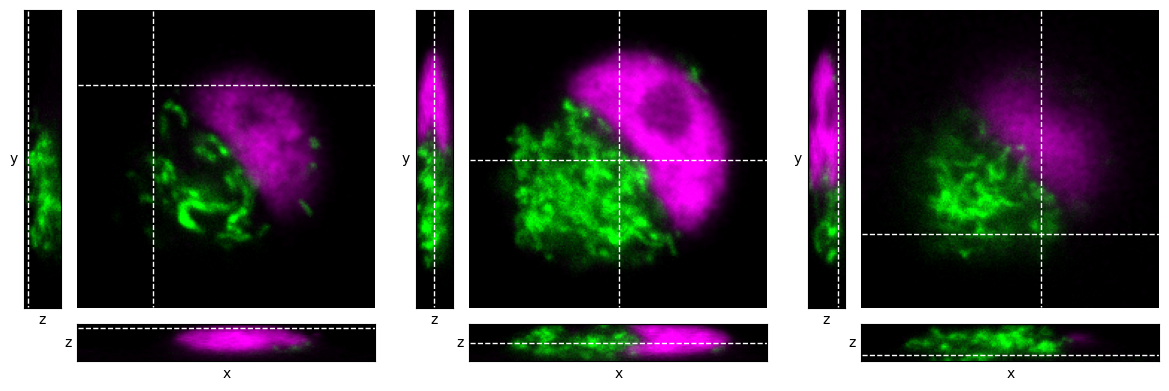
Fig. 41 Visualizing a z-stack using orthogonal slices at different locations within a z-stack, indicated by dashed lines.#
The idea of orthogonal views and projections can be combined to give orthogonal projections, as shown in Fig. 42. In this case, we don’t need to choose a point through which to pass, because the projections do not depend upon a specific slice location; rather, all pixels contribute to each projection.
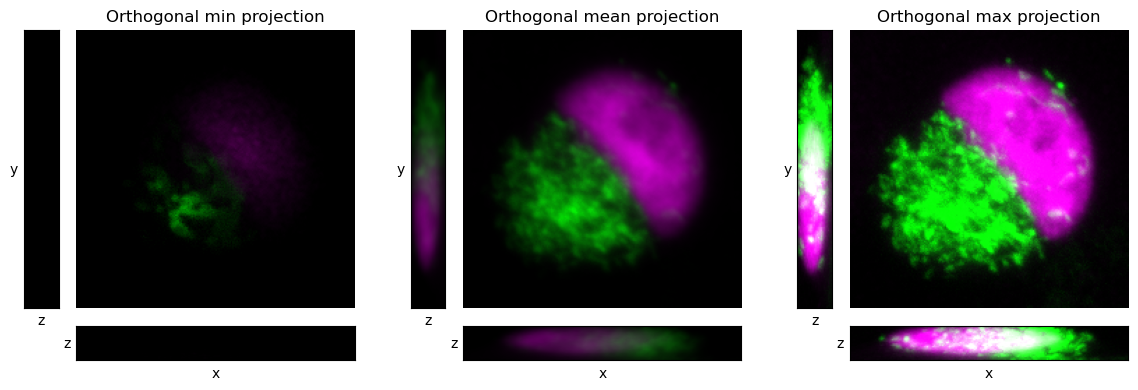
Fig. 42 Visualizing a z-stack using orthogonal projections.#