Thresholding#
Chapter outline
Image segmentation is the process of detecting objects in an image
Global thresholding identifies pixel values above or below a particular threshold
The choice of threshold can introduce bias
Automated thresholding methods can often determine a good threshold based upon the image histogram and statistics – but only if certain assumptions are met
Thresholding is more powerful when combined with filtering & subtraction
Introduction#
Before we can measure anything in an image, we first need to detect it.
Sometimes, ‘detection’ might involve manually drawing regions of interest (ROIs). However, this laborious process does not scale very well. It can also be rather subjective.
In this chapter, we will begin to explore alternative ways to identify objects within images. An ‘object’ is something we want to detect; depending upon the application, an object might be a nucleus, a cell, a vessel, a person, a bird, a car, a helicopter… more or less anything we might find in an image.
This process of detecting objects is called image segmentation. If we can automate image segmentation, this is not only likely to be much faster than manually annotating regions but should also give more reproducible results.
Binary & labeled images#
Image objects are commonly represented using binary images.
Each pixel in a binary image can have one of two values. Usually, these values are 0 and 1. In some software (including ImageJ) a binary image has the values 0 and 255, but this doesn’t really make any difference to how it is used: the key point for our purposes is that one of the values represents the foreground (i.e. pixels that are part of an object), and the other value represents the background.
For the rest of this chapter, we will assume that our binary images use 0 for the background (shown as black) and 1 for the foreground (shown as white).
This is important: if we can generate a binary image in which all our objects of interest are in the foreground, we can then use this binary image to help us make measurements of those objects.
One way to do this involves identifying individual objects in the binary image by labeling connected components. A connected component is really just a connected group of foreground pixels, which together represent a distinct object. By labeling connected components, we get a labeled image in which the pixels belonging to each object have a unique integer value. All the pixels with the same value belong either to the background (if the value is 0) or to the same object.
If required, we can then trace the boundaries of each labeled object to create regions of interest (ROIs), such as those used to make measurement in ImageJ and other software.

Fig. 63 Examples of a grayscale (blobs.gif), binary and labelled image. In (C), each label has been assigned a unique color for display. In (D), ROIs have been generated from (C) and superimposed on top of (A). It is common to use a LUT for labeled images that assigns a different color to each pixel value.#
For that reason, a lot of image analysis workflows involve binary images along the way. Most of this chapter will explore the most common way of generating a binary image: thresholding.
Connectivity
Identifying multiple objects in a binary image involves separating distinct groups of pixels that are considered ‘connected’ to one another, and then creating a ROI or label for each group. Connectivity in this sense can be defined in different ways. For example, if two pixels have the same value and are immediately beside one another (above, below, to the left or right, or diagonally adjacent) then they are said to be 8-connected, because there are 8 different neighboring locations involved. Pixels are 4-connected if they are horizontally or vertically adjacent, but not only diagonally.
The choice of connectivity can make a big difference in the number and sizes of objects found, as the example on the right shows (distinct objects are shown in different colors).
What do you suppose 6-connectivity and 26-connectivity refer to?
6-connectivity is similar to 4-connectivity, but in 3D. If all 3D diagonals are considered, we end up with each pixel having 26 neighbors.
Global thresholding#
The easiest way to segment an image is by applying a global threshold. This identifies pixels that are above or below a fixed threshold value, giving a binary image as the output.
Global thresholding can be thought of as a point operation because the output is based solely on the value of each pixel, and not its location or its neighbors. For a global threshold to work, the pixels inside objects need to have higher or lower values than the other pixels. We will look at image processing tricks to overcome this limitation later, but for now we will focus on examples where we want to detect objects have values that are clearly distinct from the background – and so global thresholding could potentially work.
Thresholding using histograms#
It’s possible to tell quite a lot about an image just by looking at its histogram.
Take the following example:
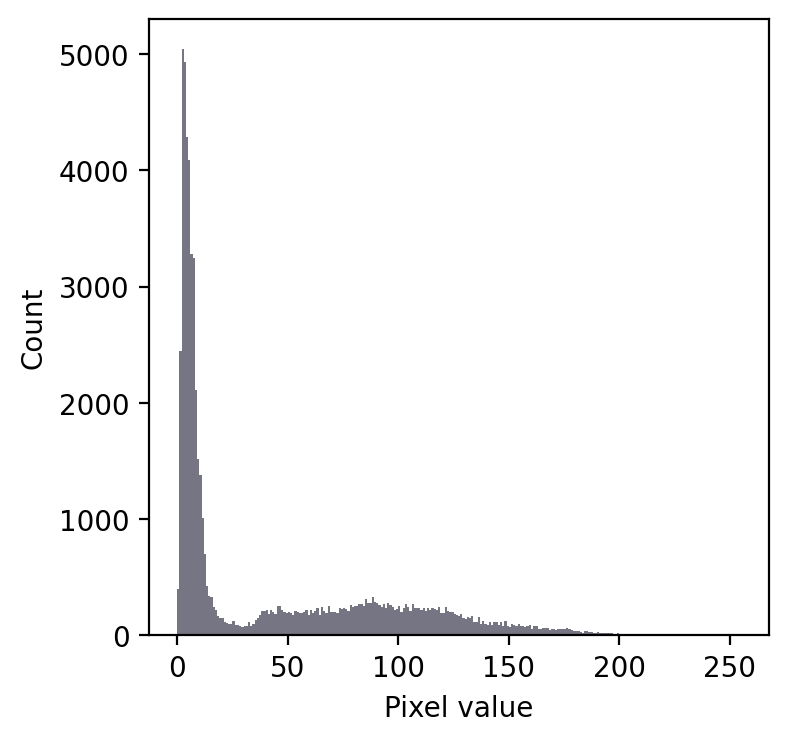
Even without seeing the image, we can make some educated guesses about its contents.
Firstly, there is a large peak to the left and a much shallower peak to the right. This suggests that there are at least two distinct regions in the image. Since the background of an image tends to contain many pixes with similar values, I would guess that we might have an image with a dark background.
In any case, a threshold around 20-25 looks like it would be a good choice to separate the regions… whatever they may be.
If we then look at the image, we can see that we have in fact got a fluorescence image depicting two nuclei. Applying a threshold of 20 does achieve a good separation of the nuclei from the background: a successful segmentation.
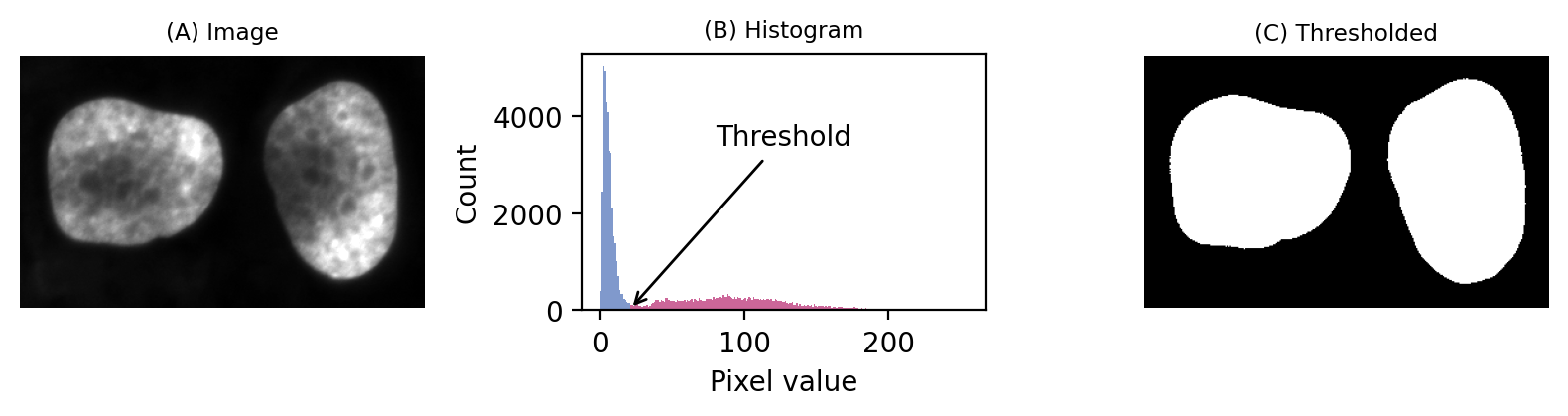
Fig. 64 A simple fluorescence image containing two nuclei. We could determine a potentially useful threshold based only on looking at the histogram.#
Admittedly, that was a particularly easy example. We should try a slightly harder one.
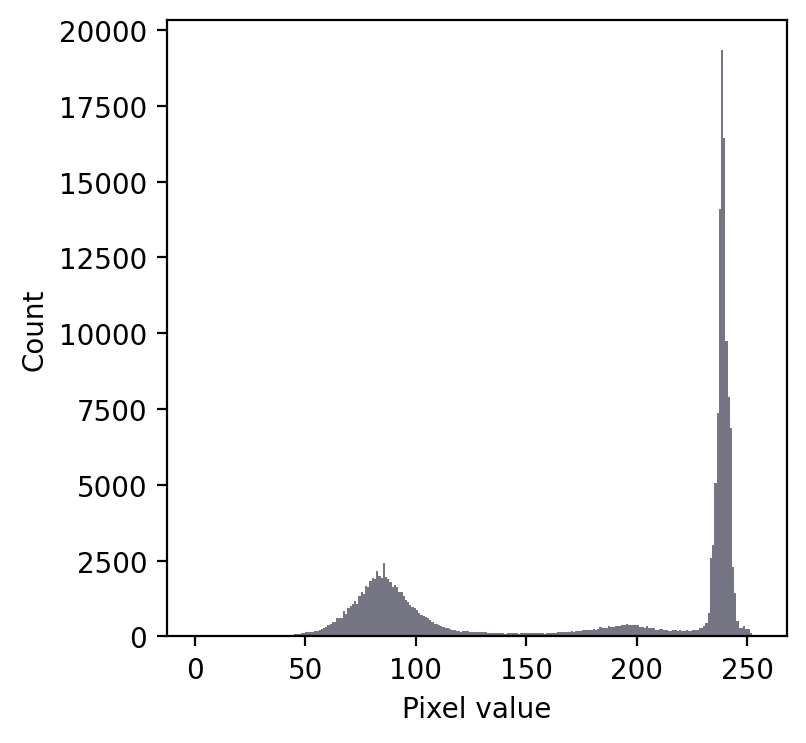
We still have a large peak, but this time it is towards the right. So I would guess a light background rather than a dark one.
But the problem is that we seem to have two shallower peaks to the left. That suggests at least three different classes of pixels in the image.
From visual inspection, we might suppose a threshold of 140 would make sense. Or perhaps around 220. It isn’t clear.
This time, we do need to look at the image to decide. Even then, there is no unambiguously ‘correct’ threshold. Rather, the one we choose depends upon whether our goal is to identify the entire leaf or rather just the darkest region.
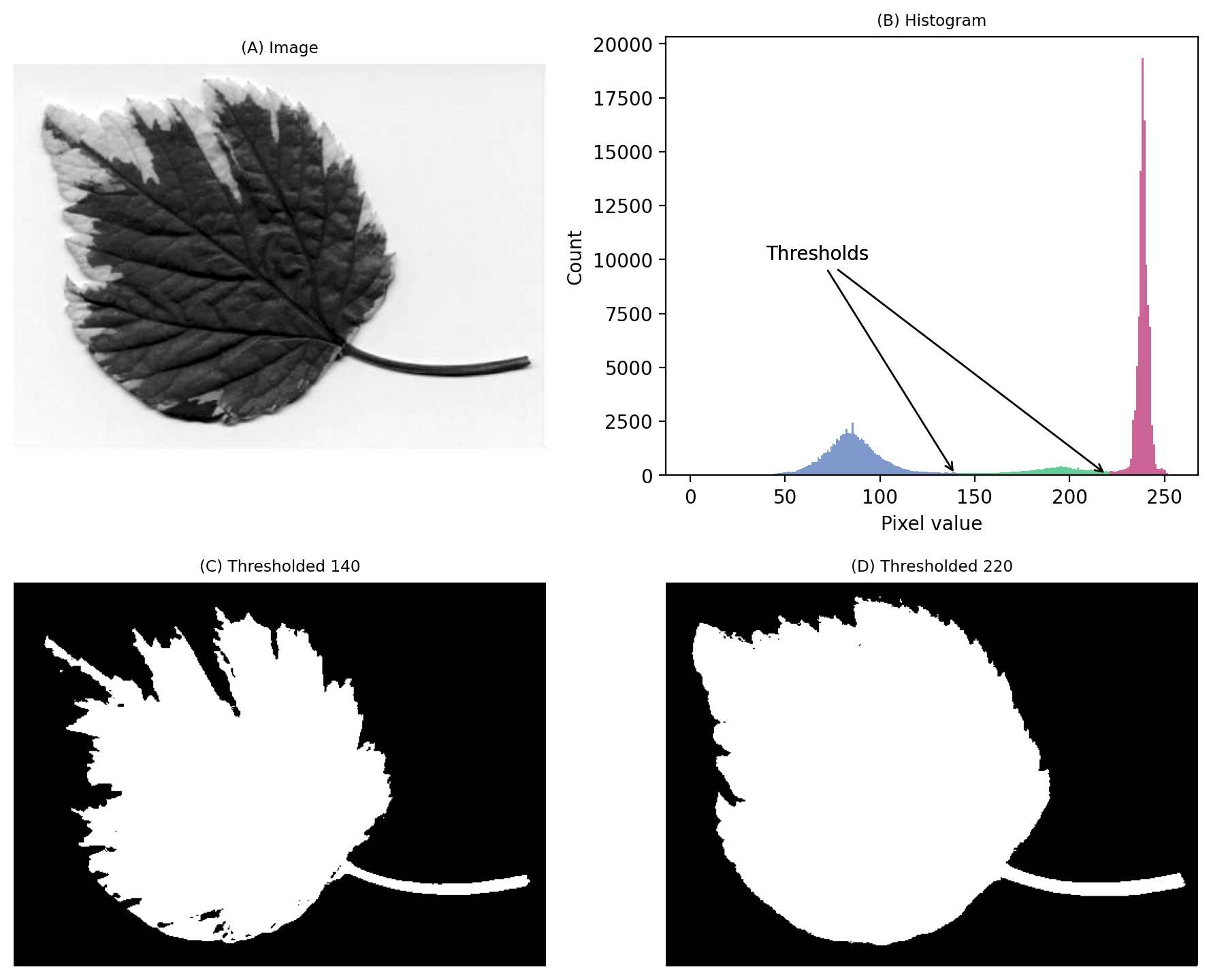
Fig. 65 An image where evaluating the histogram suggests two candidate thresholds. The ‘correct’ threshold depends upon the desired outcome. Note that here we identify pixels below the threshold value, rather than above, because the background is ligher.#
Histograms can help us choose thresholds
Histograms can be really useful when choosing threshold values – but we need to also incorporate knowledge of why we are thresholding.
The importance of the threshold choice#
We’ve seen that histograms can help us identify suitable thresholds, but they don’t absolve us of the need to think. This is particularly evident when objects are not very distinct. The exact choice of threshold can then be crucial.
Fig. 66 shows an example where the goal is to detect the bright spots (lysosomes). No single global threshold can give us perfect results, but at first glance many different thresholds can appear to give somewhat sensible results. The histogram gives, at best, a vague hint where a good threshold may lurk.
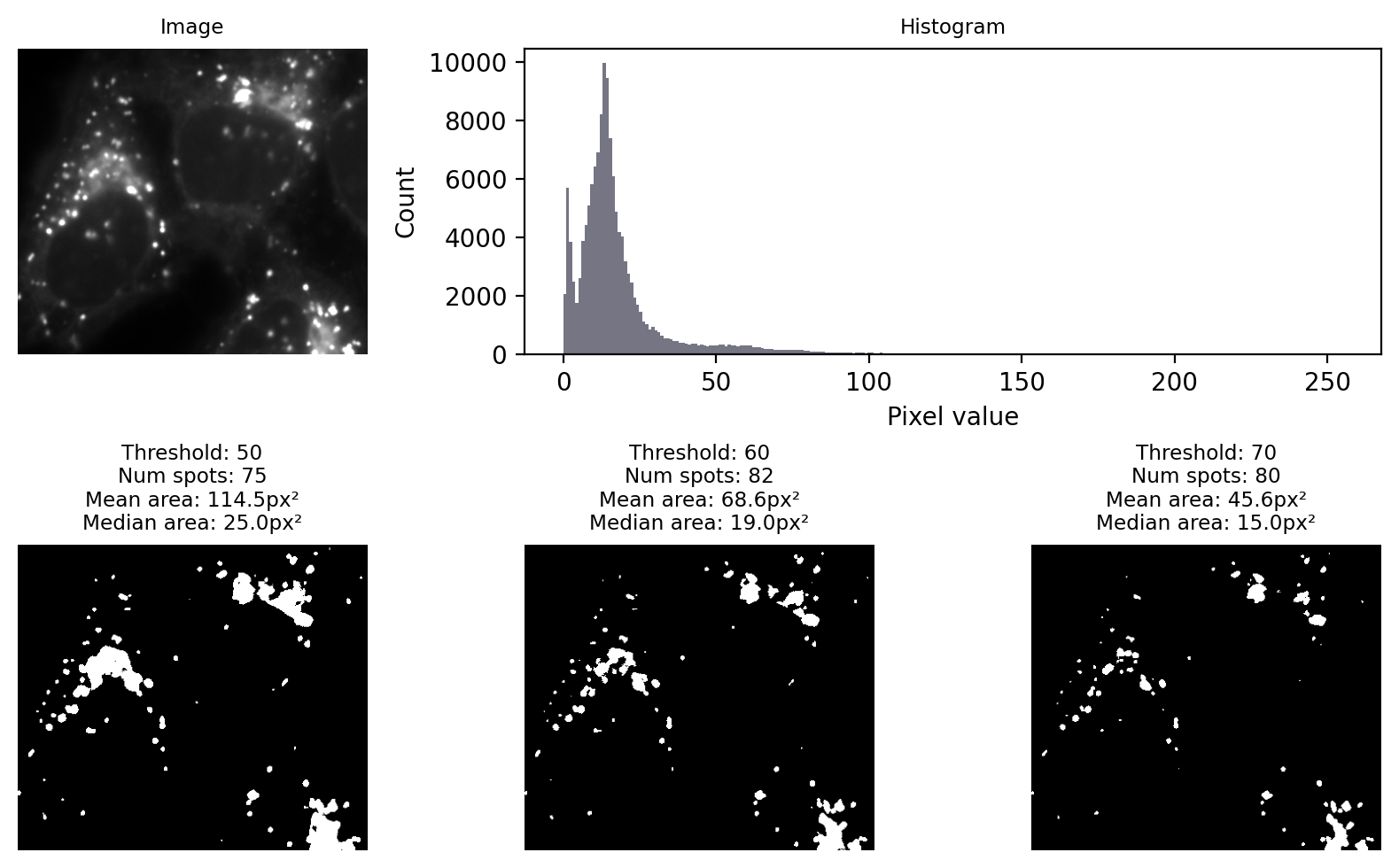
Fig. 66 Applying different manually-chosen thresholds to the same image can give quite different results.#
I would like to convey three main messages from Fig. 66:
The choice of threshold is crucial, influencing the numbers and areas of spots
A threshold that is too low tends to make structures bigger & merge some together
A threshold that is too high tends to make structures smaller & miss some
Choosing a threshold manually gives a huge opportunity to introduce bias
We should consider our errors when selecting output metrics. For example, if we needed to estimate the size of a spot from any of these results then the median is likely to be preferable, because it is less impacted by artificially large spots caused by merging.
A fourth point I would like to make is that visualization matters too. Looking only at the binary images, it is difficult to really evaluate any of the results. It helps enormously to overlay the detected regions on top of the original image (Fig. 67). From this we can see much more clearly that none of the results are terribly good: every threshold we tried misses some spots and merges others.
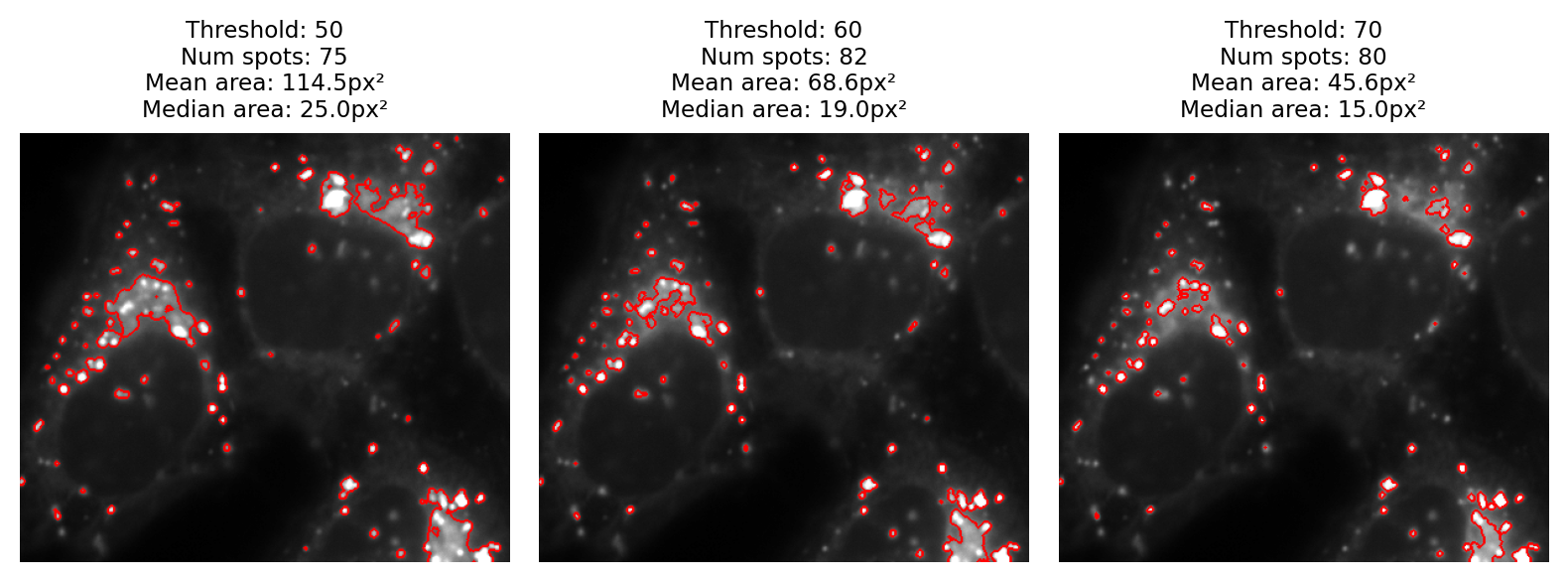
Fig. 67 The binary images of Fig. 66 viewed as overlays instead.#
Beware summary plots!
I sometimes sit in lab meetings where people discuss their image analysis results without showing a single image. I don’t approve of this at all.
It’s easy to generate summary data with image analysis. In fact, it’s disturbingly easy to generate vastly different – even conflicting – summary data by analyzing the same images in different ways. But, most worryingly of all, one can often concoct a biologically-plausible-sounding story around almost any results.
It’s crucial to visualize what is being detected and measured in each image, not just a spreadsheet or plot of the results. This is especially important when applying batch processing to many images at once. It’s tempting to check a few images and then trust the summary spreadsheet for the next 10,000, but I think there is no substitute for visualizing all (or at least a large proportion) of the images themselves.
For that reason, I would argue that devising an efficient visualization strategy is every bit as important as devising an analysis strategy.
Image overlays are often a good way to do this: for each image you analyze, create an RGB copy that outlines everything that was detected and measured. Ideally, this would have brightness and contrast settings defined in such a way that you can see at a glance when something has gone wrong. You might only look at each image for a fraction of a second through Windows Explorer or Mac Finder, but that can be enough to spot issues that would otherwise be missed.
In the last section we’ll see how applying preprocessing steps to the image can allow us to reduce the proportion of spots that are merged or missed. But first we’ll consider how to automate the threshold choice.
Automated thresholds#
We don’t want to choose thresholds manually if we can avoid it, because it affords so much room for bias. On the other hand, there’s no always-applicable strategy to determine a threshold automatically; images vary too much.
Nevertheless, there are some widely-used techniques capable of determining reasonable thresholds for many images based upon the histogram. Each one is based upon some underlying assumptions about the histogram shape or image statistics. If these assumptions are met, the method often performs well; if not, it may perform well sometimes and disastrously at other times.
In this section, we’ll look at several of the most common automated thresholding methods using three images. Each image exhibits a different kind of histogram that is commonly found in bioimages:
Bimodal: with two distinct peaks, corresponding to foreground and background
Unimodal: mostly background noise, with some interesting signal at one end
Dominant background: one large background peak, with a long tail of foreground pixels
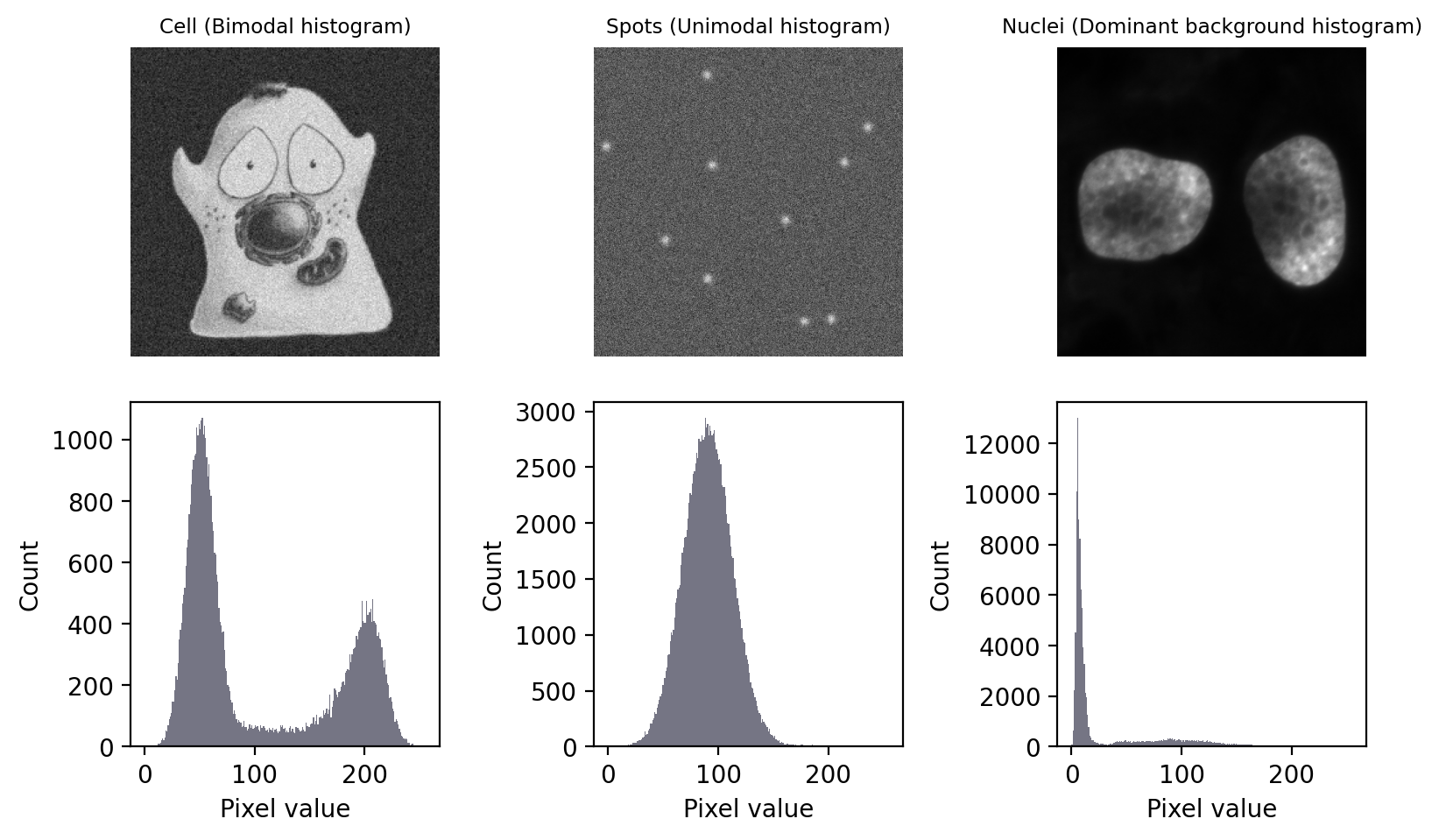
Fig. 68 Images with three different types of histogram.#
Otsu’s method#
By its nature, global thresholding assumes that there are two classes of pixel in the image – those that belong to interesting objects, and those that do not – and pixels in each class have different intensity values [1]. In principle, if we could identify the pixels for each of the two classes, we could calculate statistics such as the mean and variance (i.e. standard deviation squared) for them both separately.
Otsu’s method, introduced in 1979, has become an extremely popular approach to determining a threshold. It’s commonly described, somewhat intimidatingly, as ‘minimizing the intra-class intensity variance’. In essence, calculating a threshold using Otsu’s method involves adding the variance of the background pixels to the variance of the foreground pixels, for all possible thresholds. The threshold that is selected is the one for which the sum of the variances is smallest.
We can think of this as trying to keep the distributions of foreground and background pixels ‘compact’: two peaks that spread as little as possible.
Otsu’s method performs very well on data with a bimodal histogram, with a deep valley in between. Unfortunately, a lot of microscopy images don’t have clearly bimodal histograms, and so the method may not be such a good choice.
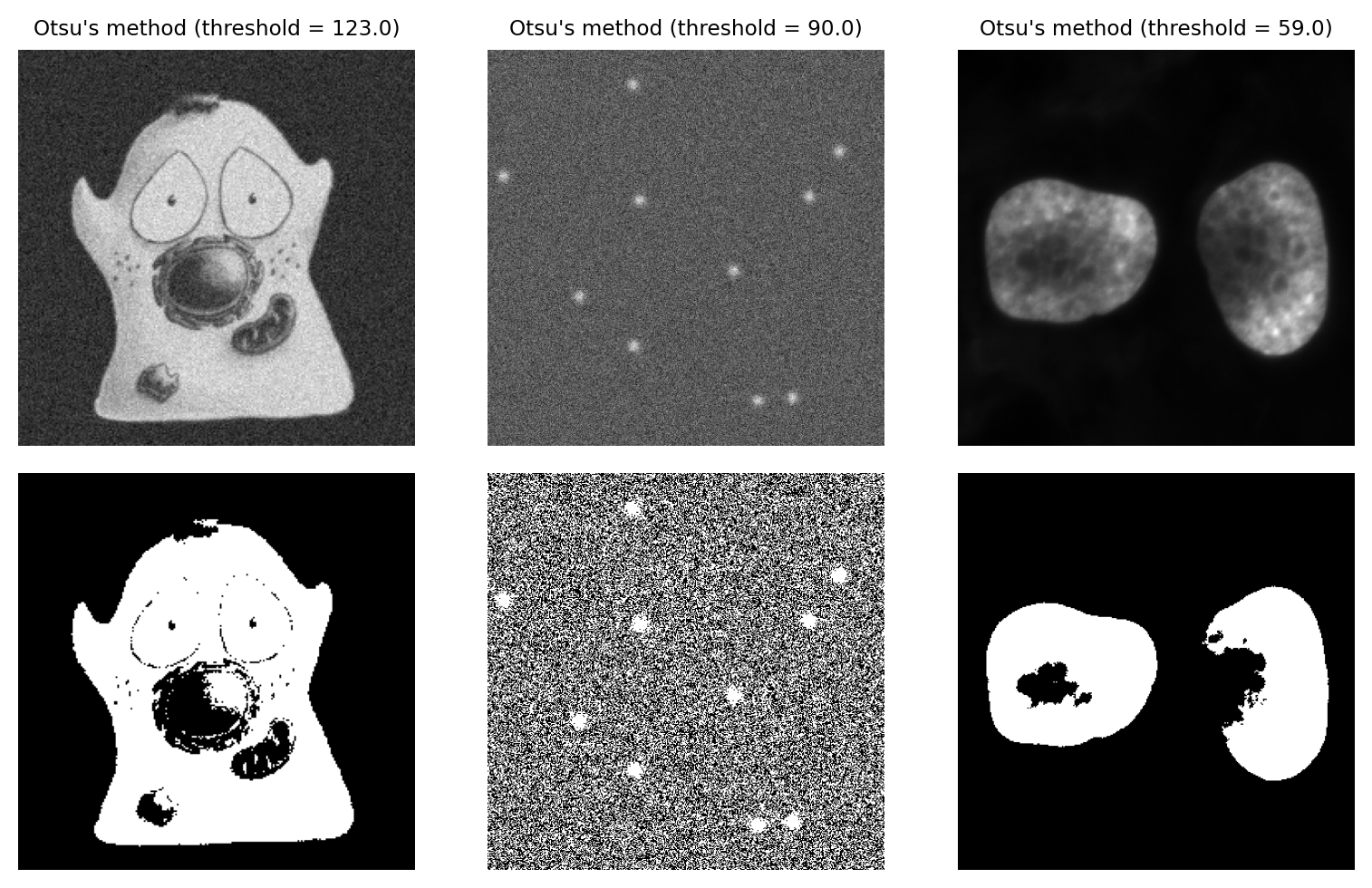
Fig. 69 Thresholding using Otsu’s method. This performs best on the cell image with a bimodal histogram. For the spots image, there is no separation between peaks to find; as a result, approximately half the pixels are identified as foreground. The method also performs quite poorly for the nucleus image, despite this previously being identified as an ‘easier’ image for thresholding.#
Minimum method#
The Minimum method provides an alternative threshold that also assumes a bimodal histogram.
The starting point is the image histogram. As can be seen in Fig. 68, the counts tend to be somewhat ‘noisy’ with lots of tiny spurious peaks. The Minimum method operates by smoothing the histogram, replacing each count value with the average of itself and the neighboring counts. By repeating this process, eventually the spurious peaks are removed until (hopefully) precisely two peaks remain. The threshold is then the location of the deepest point in the valley between those peaks.
The result of this process is illustrated in Fig. 70.
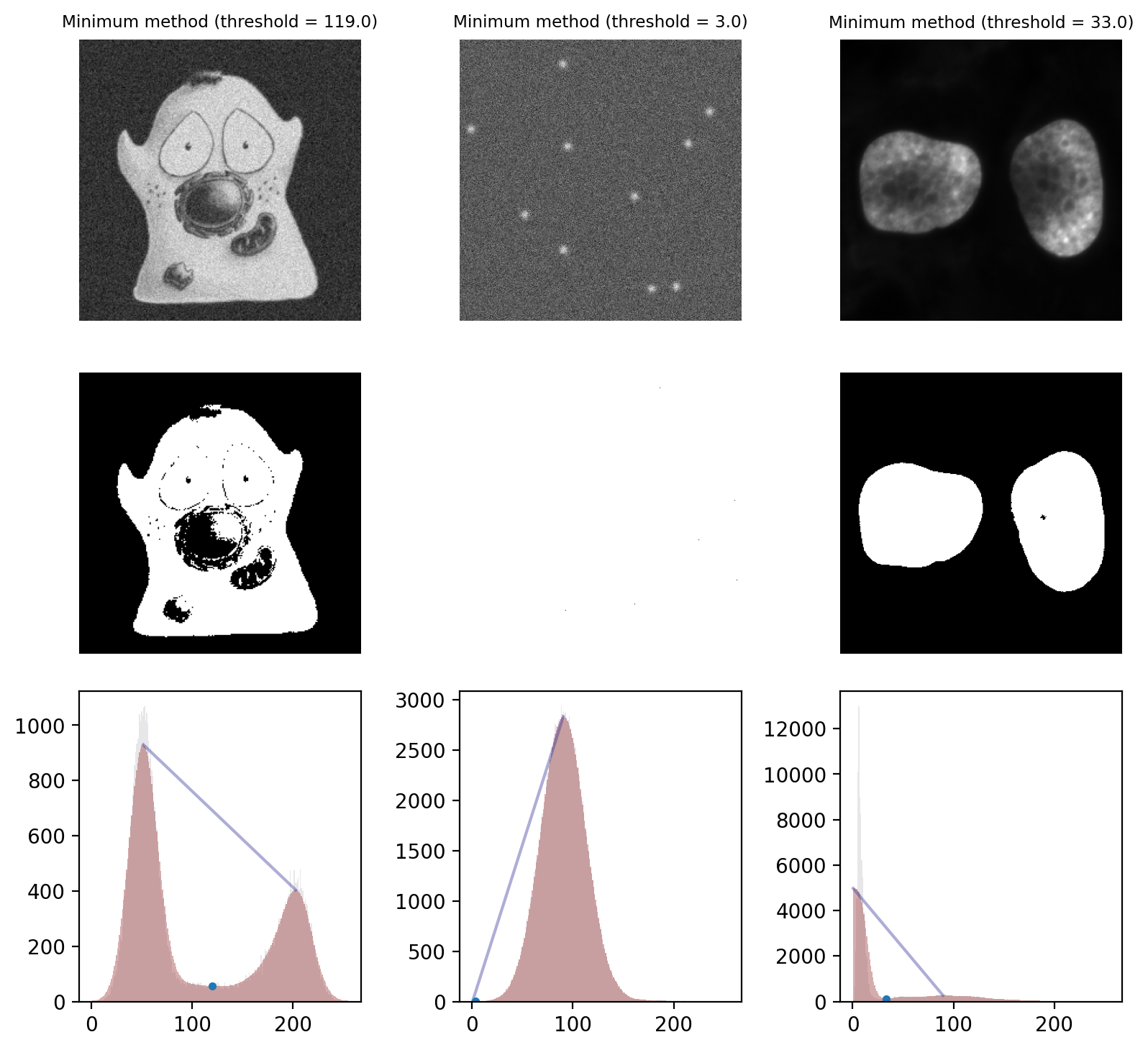
Fig. 70 Thresholding using the Minimum method. The smoothed histograms used in the calculation are shown in red, with the original histograms shown (faintly) in gray. A line connecting the two final peaks is also included, and the threshold marked with a dot.
This works well on the cells image and quite well on the nuclei image. However it fails badly on the spots image, where almost everything is detected as foreground. This is a case where the method converges (due to the image being noisy, so having lots of small peaks in the histogram) even though we might prefer it had not.#
One ‘feature’ of the Minimum method is that it is not guaranteed to converge. It is entirely possible that no amount of smoothing will result in a histogram with 2 peaks: perhaps there is only 1 peak, or none at all if all pixels are just a constant value.
This could potentially be an advantage: it may be better to return no threshold than to return a really bad one. However, in most real images we cannot count on the method not converging: it often does converge, even if it does not necessarily converge to any desirable value.
Triangle method#
The ‘triangle method’ is a popular approach to determining a threshold that works especially well in images where there is one dominant background peak, and the ideal threshold should be at the base of that peak.
The general idea is that a a line is drawn from the peak of the histogram to the last bin that contains any pixels. Then a perpendicular line is plotted to the histogram itself, and the distance to the histogram maximized. The direction of the line depends upon whether the peak is toward the left or the right of the histogram; all counts on the other side are ignored.
The width and height of the histogram are normalized to deal with the fact that pixel values and intensity counts are in completely different units, and therefore in completely different scales.
The explanation is confusing, but hopefully Fig. 71 depicts it more clearly – and provides an intuition for when and why it might be appropriate.
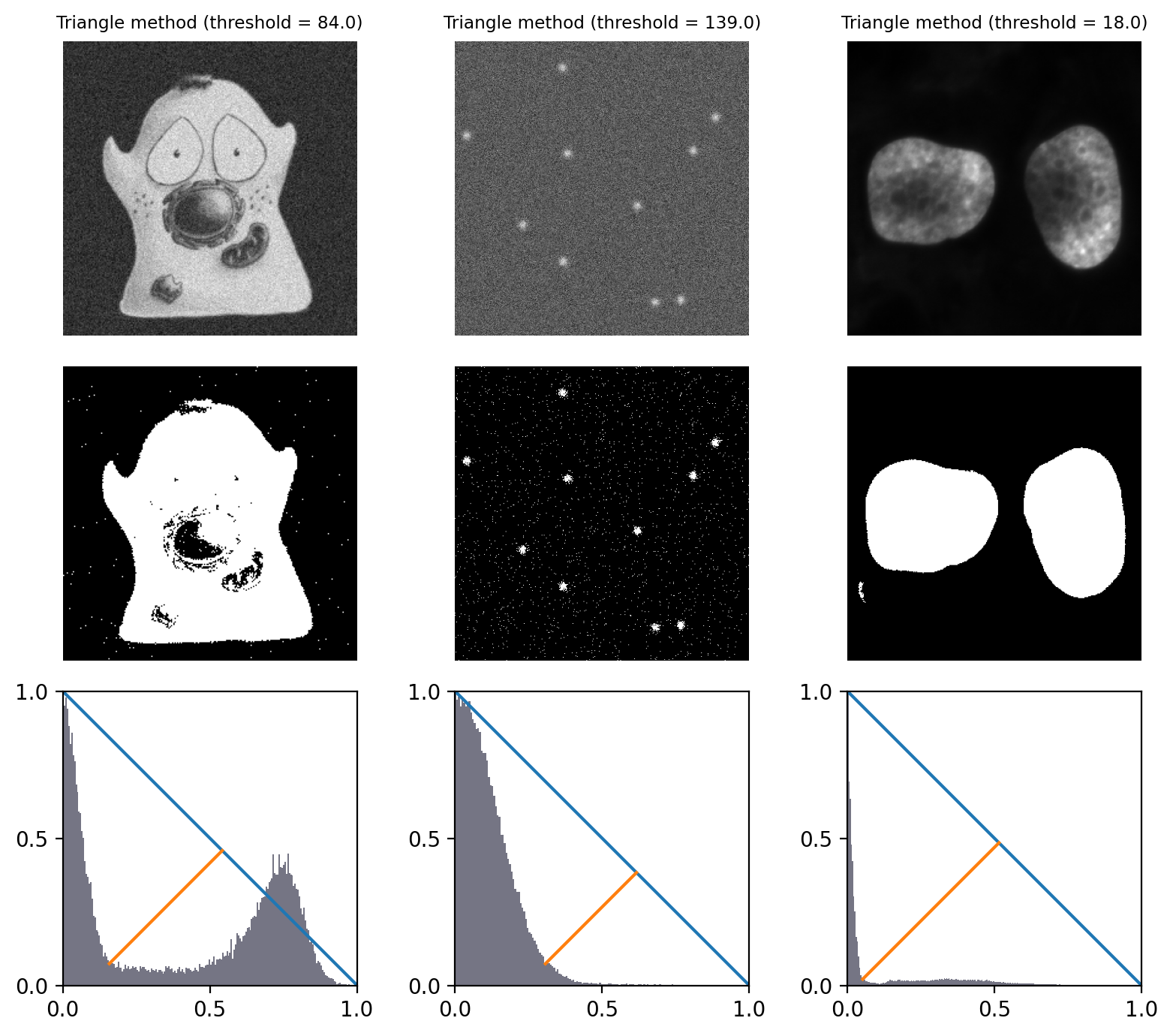
Fig. 71 Thresholding using the Triangle method. Because all example histograms have a dominant peak, this performs quite well in all cases – although tends to detect more foreground pixels in the cell image than other methods (because the threshold is at the base of the peak rather than between the two modes).
The histograms depict the triangles that give the method its name.
They have been normalized and truncated to include only the relevant part.#
Mean method#
An alternative simple approach is to skip the histogram altogether, and just use the mean of all pixel values.
This can actually give quite good reasons on many real-world images – although this may be more through luck than design. It’s not a method I typically use myself.

Fig. 72 Thresholding using the Mean method.#
Mean & Standard deviation#
We can add a bit more to the Mean method by incorporating the standard deviation, scaled by a constant. The threshold becomes mean + k x standard.deviation, where we can adjust k based upon our attitude towards sensitivity vs. specificity.
The main advantage of this approach is that it should not fail catastropically in cases where we have an image that is mostly just noise (assuming k is large enough), unlike methods that require a bimodal histogram. However the disadvantage is that it is not robust: the threshold can be pulled higher or lower by outliers, or by foreground values being very different from background values.
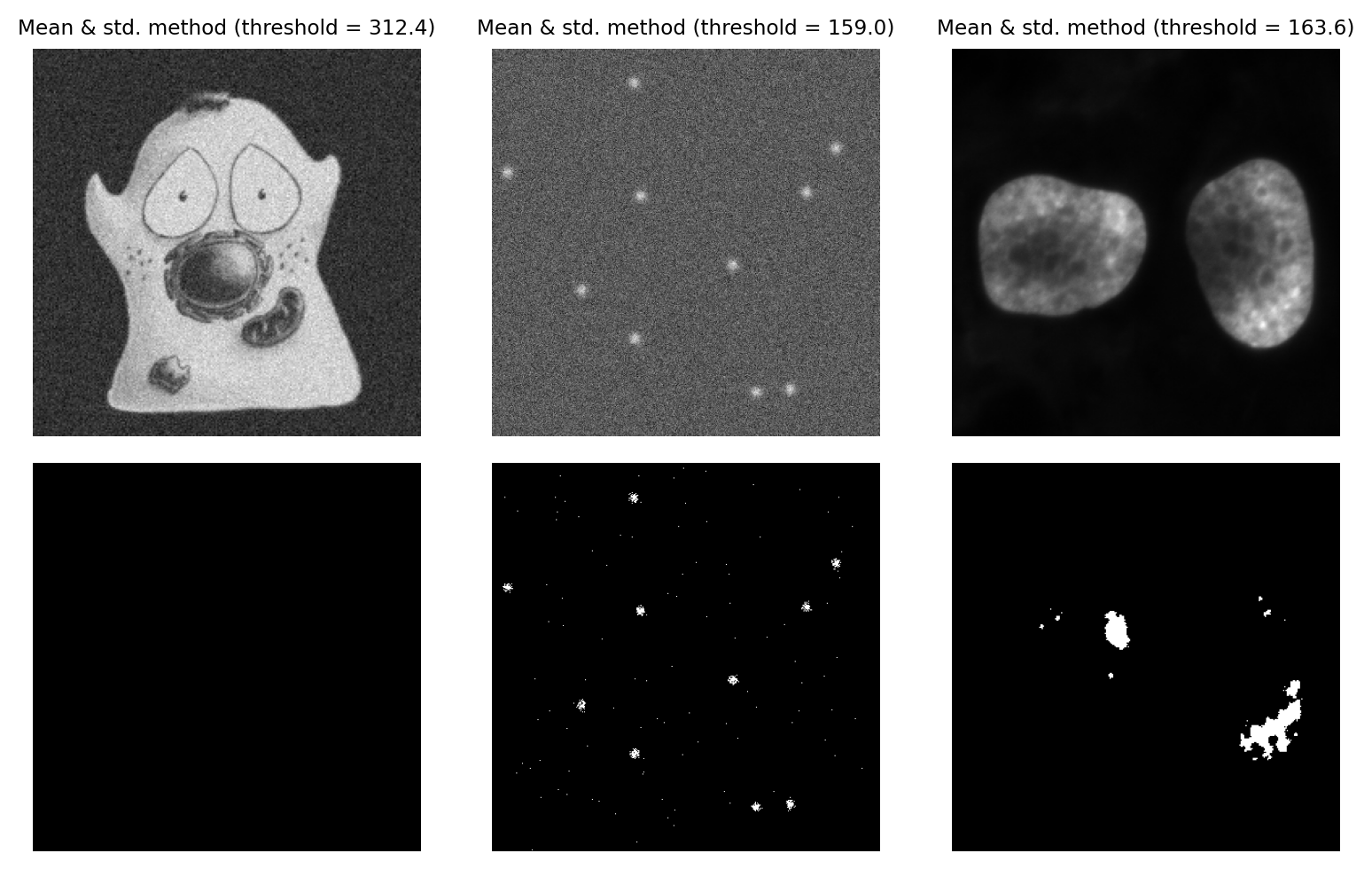
Fig. 73 Thresholding using the Mean + k x std.dev. method, with k = 3.#
Median & Median Absolute Deviation#
A more robust alternative to using the mean and standard deviation is to use the median and median absolute deviation (MAD) to determine a threshold.
If the pixel values of an image were to be sorted, the median is the value that would be in the middle. The MAD is calculated as follows:
Subtract the median from all pixels
Compute the absolute value of the result of (1) (i.e. flip the sign of negative values, so that all are positive)
Compute the median of the result of (2)
An intriguingly useful property of the MAD is that it can be scaled by 1.482 to resemble a (more robust) standard deviation. The Wikipedia article explains this in more detail.
Typically, we would use the median + k x MAD x 1.482, where we can adjust k as if it was used to scale a standard deviation. This is helpful because standard deviations are easier for (most of) us to tune.
Using the MAD to define a threshold remains fairly uncommon, but I personally like the method a lot when working with very noisy fluorescence images. The three main requirements for this method to work are:
Most of the image should be background, and noisy (a completely constant background will give a MAD of 0, and a bad threshold)
The noise should (more or less) follow a normal distribution
The image shouldn’t be too large, because calculating the median exactly is slow
The last point is not always an issue: we can calculate the median much more quickly if we use a histogram, although we may lose some precision due to the binning required when building the histogram.
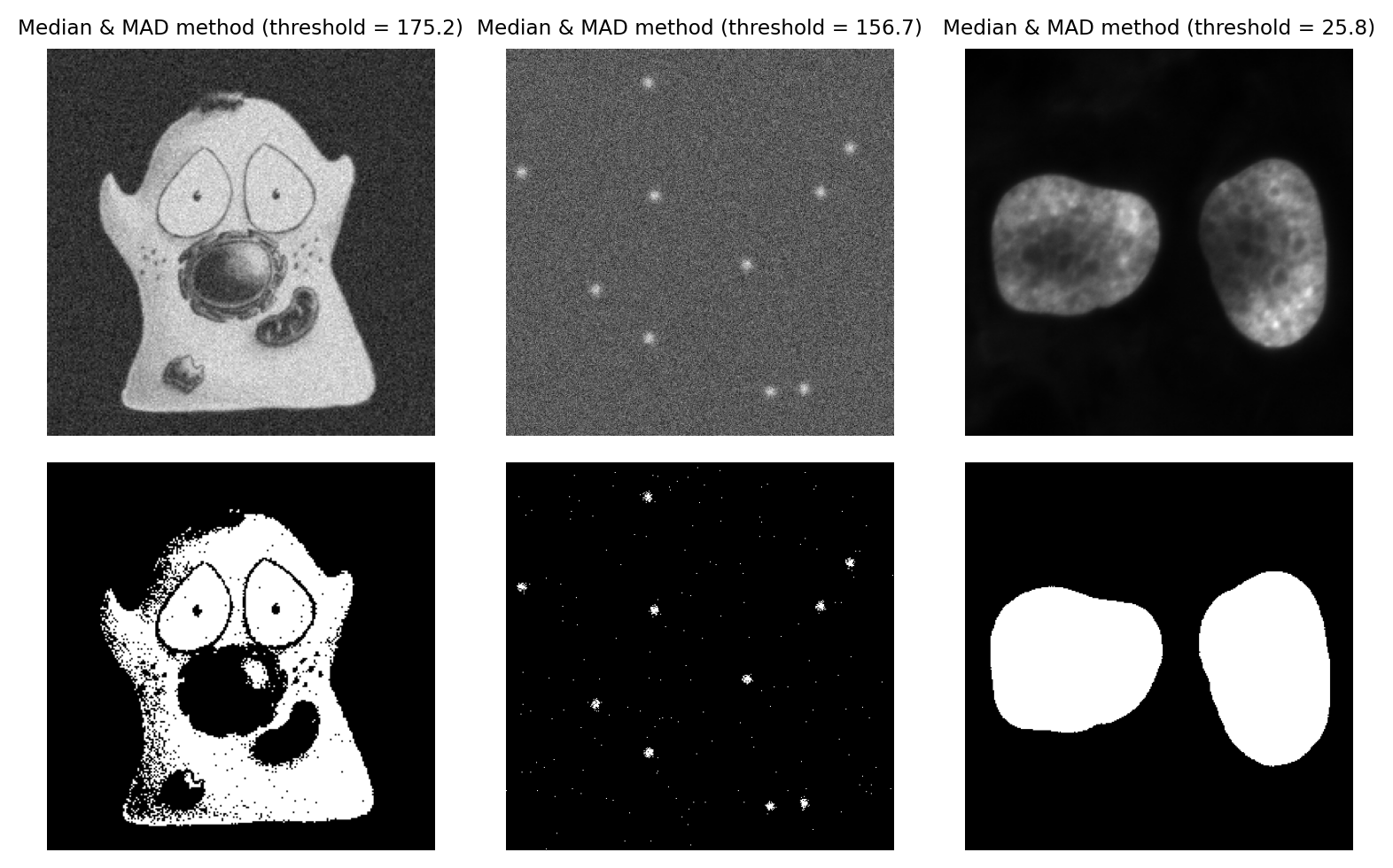
Fig. 74 Thresholding using the MAD method, with k = 3. This is a strong candiate to be my preferred method for the ‘spots’ image, because it is effective when looking for small signals buried in noise.#
Clipping confounds automated thresholds
If the data is clipped, then the statistics of the pixel values and shape of the image histogram are changed. This means that the theory underlying why an automated threshold should work might well no longer apply.
This is another reason why clipping should always be avoided!
Are automated thresholds less biased?
I sometimes see the use of automated thresholding methods justified because they are ‘less biased than manual thresholds’.
I am unconvinced.
I do agree that automated thresholds are strongly preferable to subjectively picking a threshold by eye – but only if they can be shown to work reliably for a particular dataset. A bad automated threshold can easily introduce a systematic bias that is much worse than manually setting a threshold for each image.
Thresholding difficult data#
Applying global thresholds is all well and good in easy images for which a threshold clearly exists, but in practice things are rarely so straightforward – and often no threshold, manual or automatic, produces useable results. This section anticipates the next chapter on filters by showing that, with some extra processing, thresholding can be redeemed even if it initially seems to perform badly.
Thresholding noisy data#
Noise is one problem that affects thresholds, especially in live cell imaging.
The top half of Fig. 75 reproduces the nuclei from Fig. 64 but with extra noise added to simulate less than ideal imaging conditions. Although the nuclei are still clearly visible in the image (A), the two classes of pixels (which were previously easy to separate) have now been merged together in the histogram (B). The triangle threshold method, which had performed well before, now gives less attractive results (C), because the noise has caused the ranges of background and nuclei pixels to overlap.
However, if we apply a Gaussian filter to smooth the image, a lot of the random noise is reduced (see Filters). This results in a histogram dramatically more similar to that in the original, (almost) noise-free image, and the threshold is again quite successful (F).
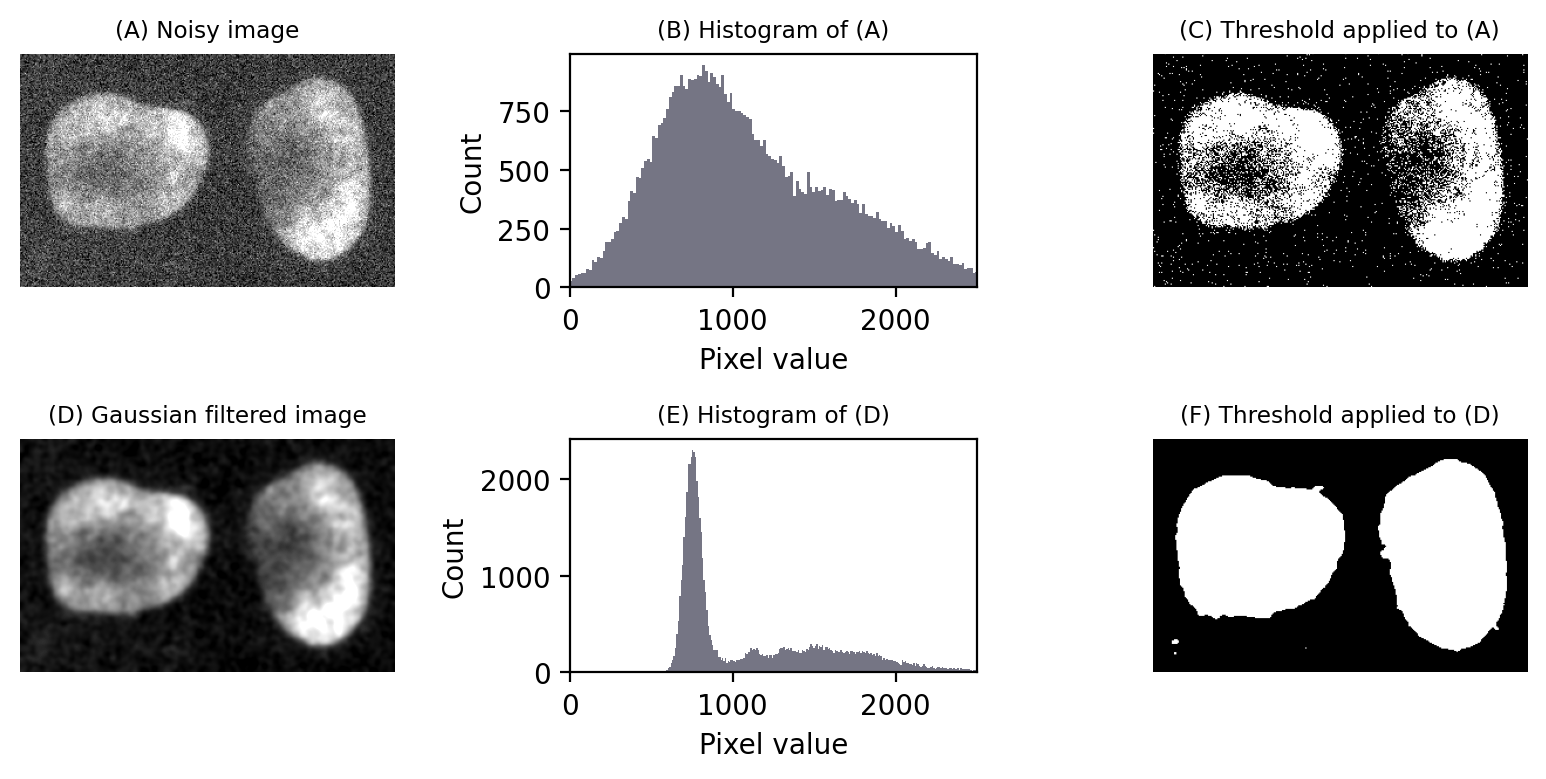
Fig. 75 Noise can affect thresholding. After the addition of simulated noise to the image in Fig. 64, the distinction between nuclei and non-nuclei pixels is much harder to identify in the histogram (B). Any threshold would result in a large number of incorrectly-identified pixels. However, applying a Gaussian filter (here, \(\sigma = 2\)) to reduce noise can dramatically improve the situation (E). Thresholds in (C) and (F) were computed using the triangle method.#
Local thresholding#
Another common problem is that the structures that should be detected appear on top of a background that itself varies in brightness. This was the reason no threshold performed very well in Fig. 66.
Ideally, we would like to apply a threshold that varies relative to the local background.
There are a variety of local thresholding methods available, many of which are variations on the Niblack method. This calculates the mean and standard deviation of pixels in a local window around each pixel, for example a square of 25 x 25 pixels.
A separate threshold is then generated for every pixel,defined as local_mean - k x local_std.dev. Note the sign: -k is used, because the original definition was focussed on recognizing dark text on a light background, but k itself can be a negative number if needed.
An example is shown in Fig. 76.
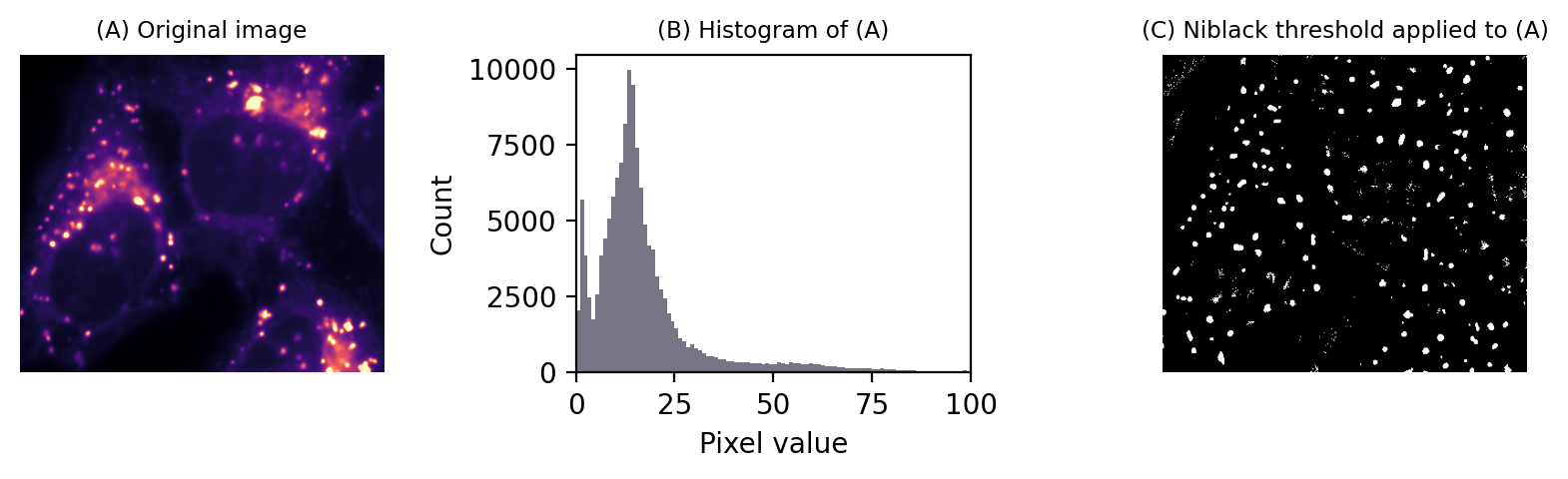
Fig. 76 Local thresholding to detect spots using Niblack’s method.#
To be honest, I don’t tend to use this approach for bioimages. I find the window size and k parameters difficult to tune, and it suffers the problem of the mean and standard deviation not being robust.
However, local thresholding becomes more interesting and powerful if we take matters into our own hands by thinking about the problem from a slightly different angle.
Suppose we had a second image that contained values equal to the thresholds we want to apply at each pixel. If we simply subtract this second image from the first, we can then apply a global threshold of 0 to detect what we want.
Alternatively, we could subtract an image with values that aren’t exactly equal to the local thresholds, but similar enough to effectively flatten out the background so that a global threshold can be applied. This then provides us access to all global automated thresholding methods, and an intuition of how the histograms ought to look for the methods to be appropriate. Fig. 77 shows this in action.
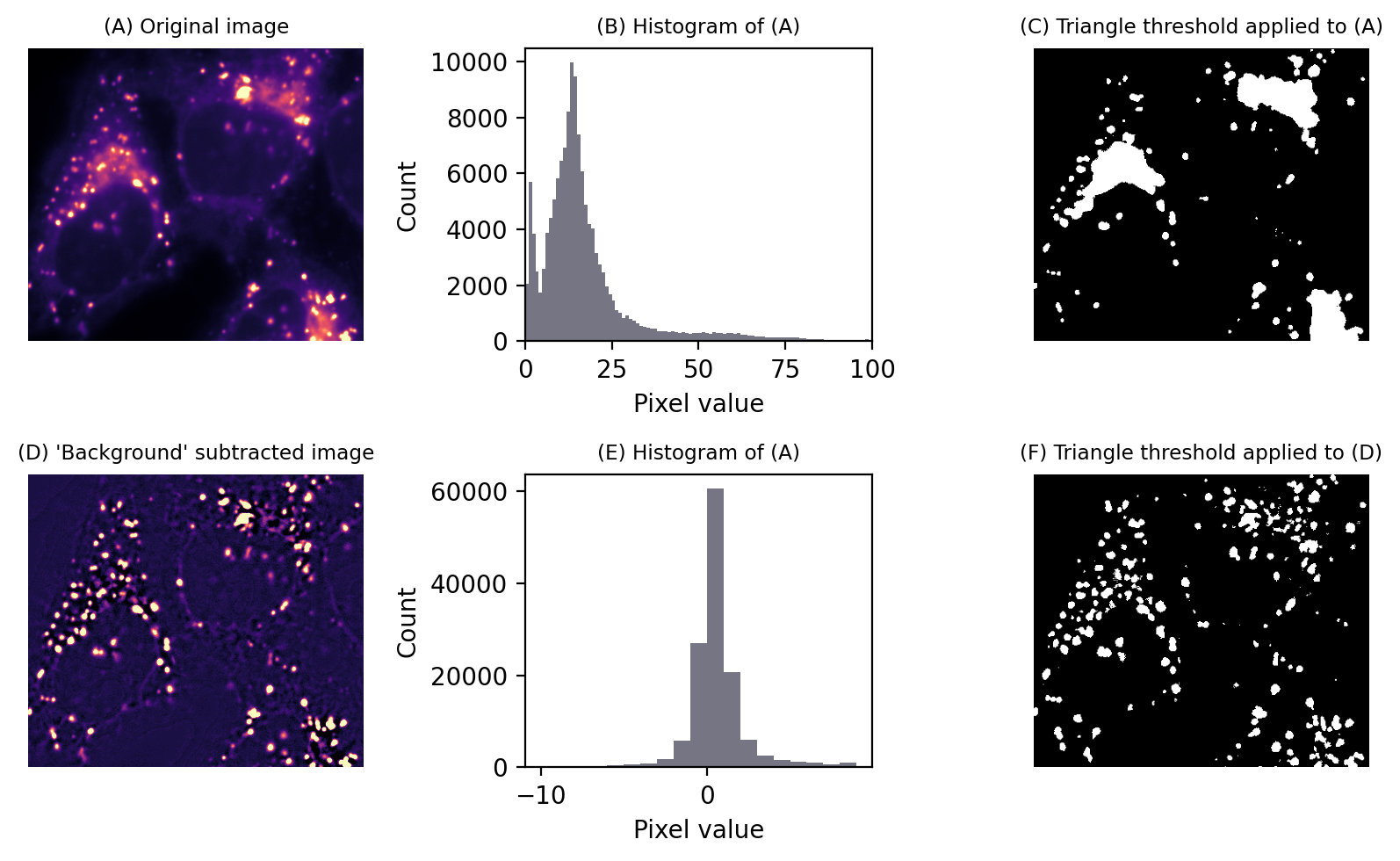
Fig. 77 Thresholding to detect structures appearing on a varying background. No global threshold may be sufficiently selective (top row). However, if a ‘background image’ can be created, (here using a large median filter), and then subtracted, a single threshold can give much better results (bottom row). This is equivalent to applying a varying threshold to the original image.#
The difficult part is creating the second image. Filters are the key, and the subject of the next chapter.