Multidimensional processing#
Chapter outline
Many processing operations can be extended beyond 2 dimensions
Adding extra dimensions can greatly increase the computational requirements
Introduction#
So far, in terms of image processing we have concentrated only on 2D images. Most of the operations we have considered can also be applied to 3D data – and sometimes data with more dimensions, in cases where this is meaningful.
This very short overview of multidimensional processing describes a few of the issues to consider when extending analysis beyond two dimensions, and gives some pointers towards specialist tools.
We will focus on 3D images: specifically, on z-stacks.
What about channels and time?
The 5 main dimensions commonly encountered in bioimage analysis are x, y, z, channels, and time. The first three are similar (spatial), whereas the last two are somewhat different.
Although we considered channels to be another dimension in previous chapters, we don’t usually apply operations (e.g. filters, thresholds) across channels or time. Rather, we usually split the channels or timepoints during processing (e.g. to detect nuclei from one channel and a cell boundary in a second channel), then combine the ROIs or measurements at the end.
This means that the key processing steps don’t require an extra dimension for channels or time.
In the case of time, the ‘combining’ step may involve linking objects to track them. Tools such as the fantastic Trackmate can be used for this.
nD image analysis
If a technique works for nD images, this indicates it can handle any number of dimensions.
The SciPy Multidimensional image processing package embraces this, being imported as scipy.ndimage.
Segmentation in 3D#
Image segmentation generally involves generating binary and labeled images.
Most of the processing operations we have discussed to help perform image segmentation extend naturally into 3D (and beyond), although there are some extra considerations.
Thresholding#
Thresholds are typically determined using the image histogram. This is computed from all pixels in the image – the number of dimensions does not really matter.
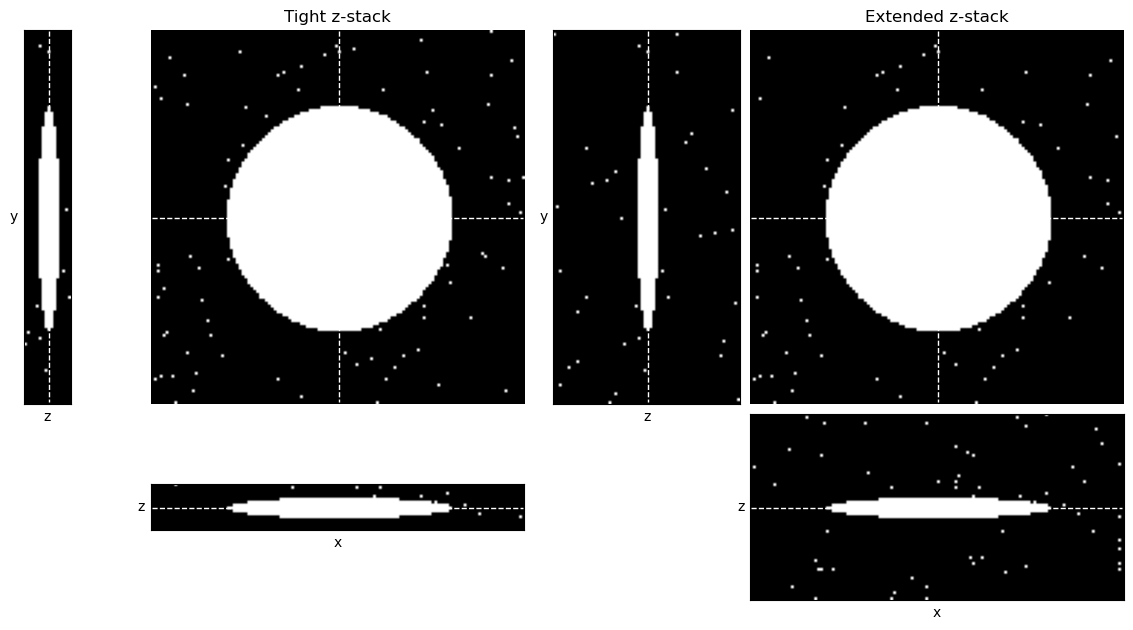
The main consideration for thresholding in 3D is whether the other z-slices could introduce any kind of sneaky bias. One occasion when that could happen is if the images are acquired with different numbers of slices, e.g. some containing more out-of-focus planes than others (Fig. 129). These extra planes could impact the histogram and image statistics, and therefore any automated thresholds. An image with many out-of-focus slices might be thresholded differently from an image with few slices.
A solution for that may be to extract a fixed number of slices from each image, for example 10 slices centered upon the volume of interest within the image. This should generally make the images more comparable.
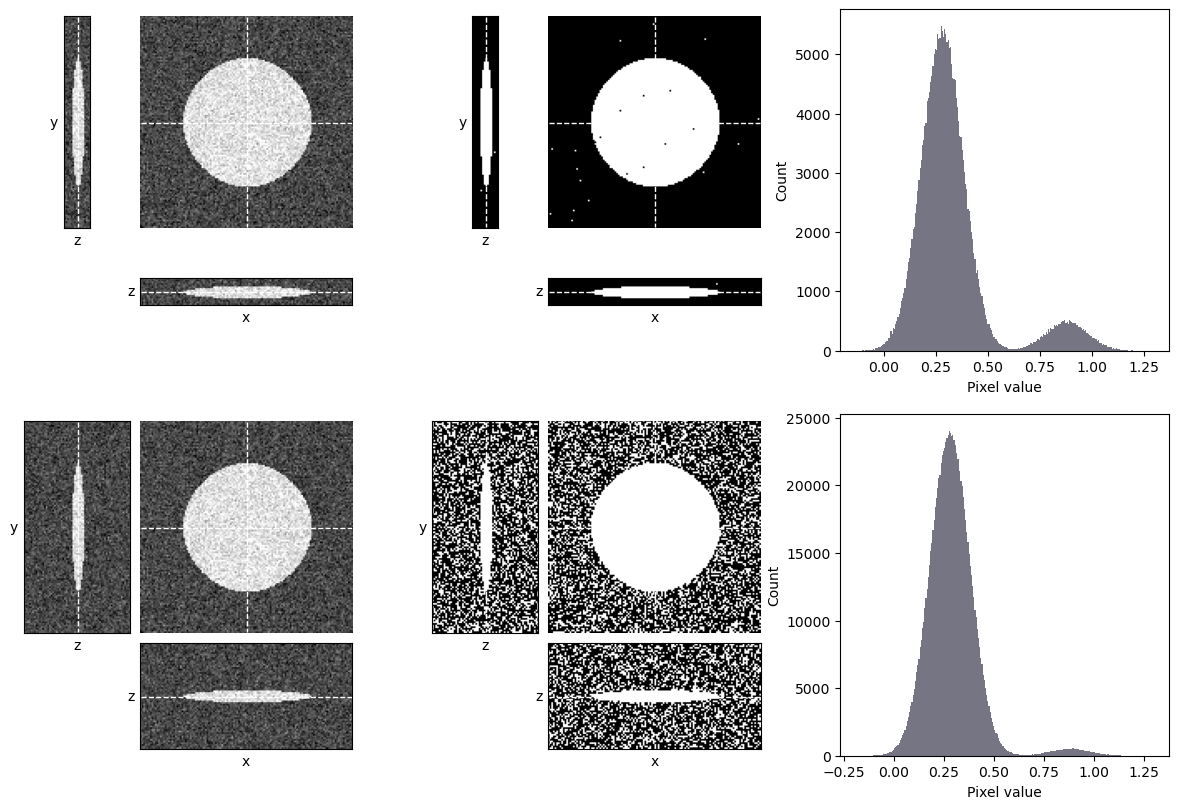
Fig. 129 Thresholding a z-stack can be influenced by the number of out-of-focus slices. Here, an automated threshold determined using Otsu’s method is applied to two z-stacks showing the same object. The top stack contains few out-of-focus slices, while the bottom stack contains the exact same data plus additional slices that contain only noise. Otsu’s method is well-suited to the top stack and performs well, however it fails badly on the bottom stack, where there is a much higher proportion of background pixels – and so the background peak is more dominant.#
How would you expect Fig. 129 to differ if the triangle method was used to determine the threshold, rather than Otsu’s method?
Here, the triangle method performs well. It sets the threshold appropriately at the foot of the background peak in both cases.
Filtering#
Linear filters can be easily extended to nD by defining a filter kernel with the desired number of dimensions. However, this can dramatically increase the computational requirements and so we need to begin considering performance.
For example, suppose we have a 3×3 filter. Following the algorithm for linear filtering described previously, we would have to perform 9 multiplications and additions to determine the value for every pixel in the output image. If our image is 1000×1000 pixels in size, that suggests 9,000,000 multiplications and additions. This seems quite a lot, but modern computers are fast so we’re unlikely to notice it.
However, if we have a 3×3×3 filter then each output pixel depends upon 27 input pixels. And the additional slices mean our image is likely to be bigger; say, 1000×1000×10 pixels. Now we have to perform calculations involving 270,000,000 pixels, i.e. a lot more. Still, even that is probably fast nowadays.
But how big can we go? An 11×11 filter involves 121 pixels. But an 11×11×11 filter involves 1331. For larger filters and images, we can rapidly increase the computations involved until processing is very slow.
The situation improves dramatically if a filter is separable. This means that instead of applying, for example, a single 11×11×11 filter (1331 coefficients) we can instead apply three separate 11×1 filters oriented along each dimension (33 coefficients).
Not all linear filters are separable, but many common ones are. This includes mean filters (depending upon neigborhood shape) and Gaussian filters. The result of applying the filter separably should be the same as the result of applying one dense multidimensional filter (Fig. 130). Some small differences may arise through the handling of rounding and bit-depths, but the improvement in performance is almost certainly worth any tiny error introduced by applying a filter separably.
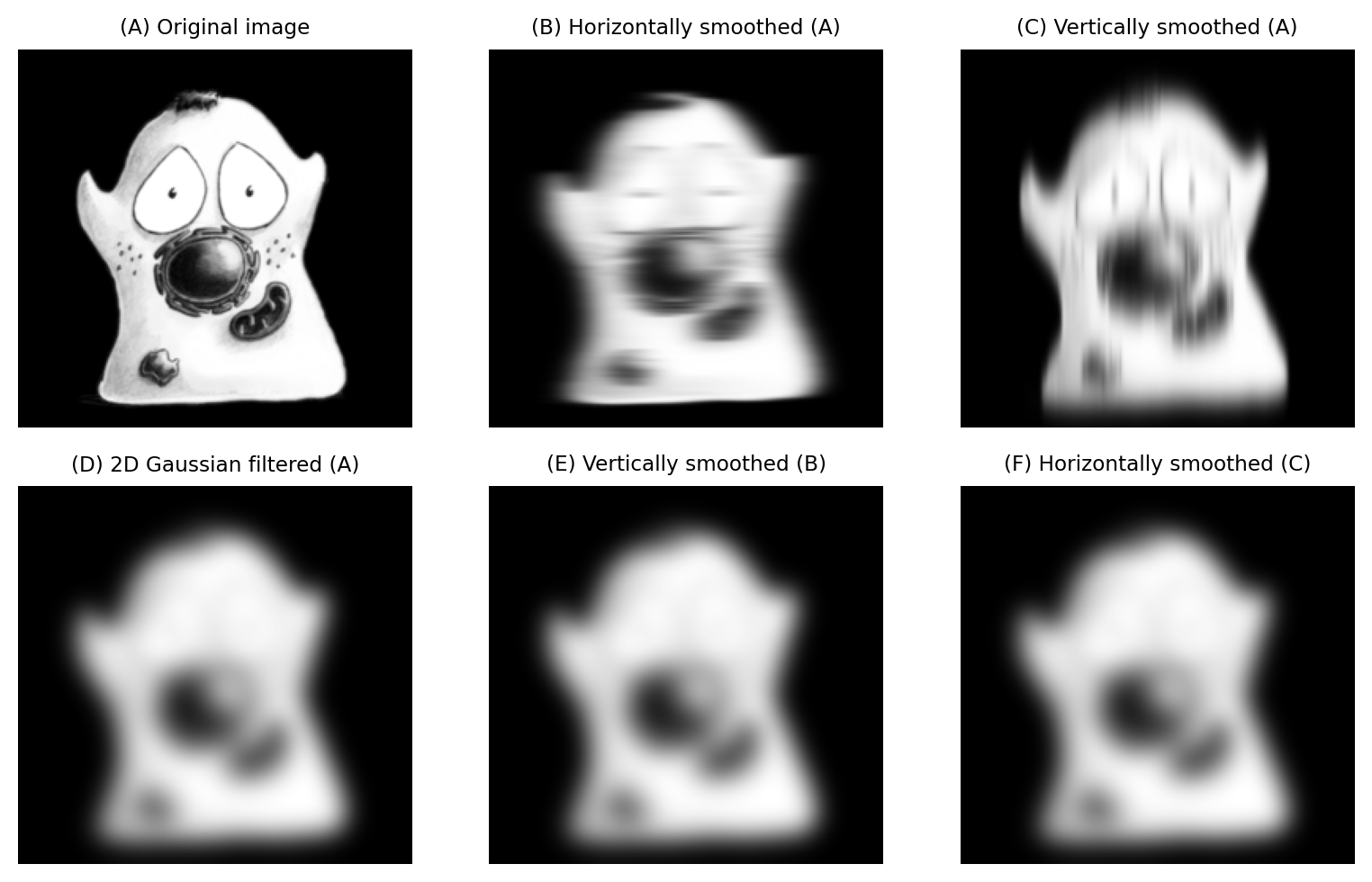
Fig. 130 2D Gaussian smoothing can be applied using a single 2D filter, or by sequentially filtering either rows or columns of the image: the end result is the same (up to rounding error). The order of the separable filtering doesn’t matter.#
Considerations are similar for nonlinear filters: when we add more dimensions, the neighborhood size can increase quickly and make the calculations slow. Separability can help with some nonlinear filters (e.g. minimum and maximum, depending on window shape), but not all. Median filters in particular are difficult to optimize, and can be extremely slow when the neighborhood is large and/or more than 2D.
Isotropy and anisotropy
As discussed Pixel size & dimensions, the pixel width and height are usually the same. For a z-stack, the z-spacing might be the same as the width and height, in which case the pixels are called isotropic. But very often the z-spacing is different, meaning that the pixels are anisotropic.
It helps to keep this in mind when choosing filter sizes. For example, I would usually set the \(\sigma\) value for a 3D Gaussian filter based upon the pixel size.
Suppose that the pixel width and height are both 0.5 µm, and the z-spacing is 1 µm. I might then choose \(\sigma_x\) = 2 px, \(\sigma_y\) = 2 px and \(\sigma_z\) = 1 px to compensate for the difference.
Note that some software may allow you to enter the \(\sigma\) in µm directly, and perform the conversion to pixels automatically.
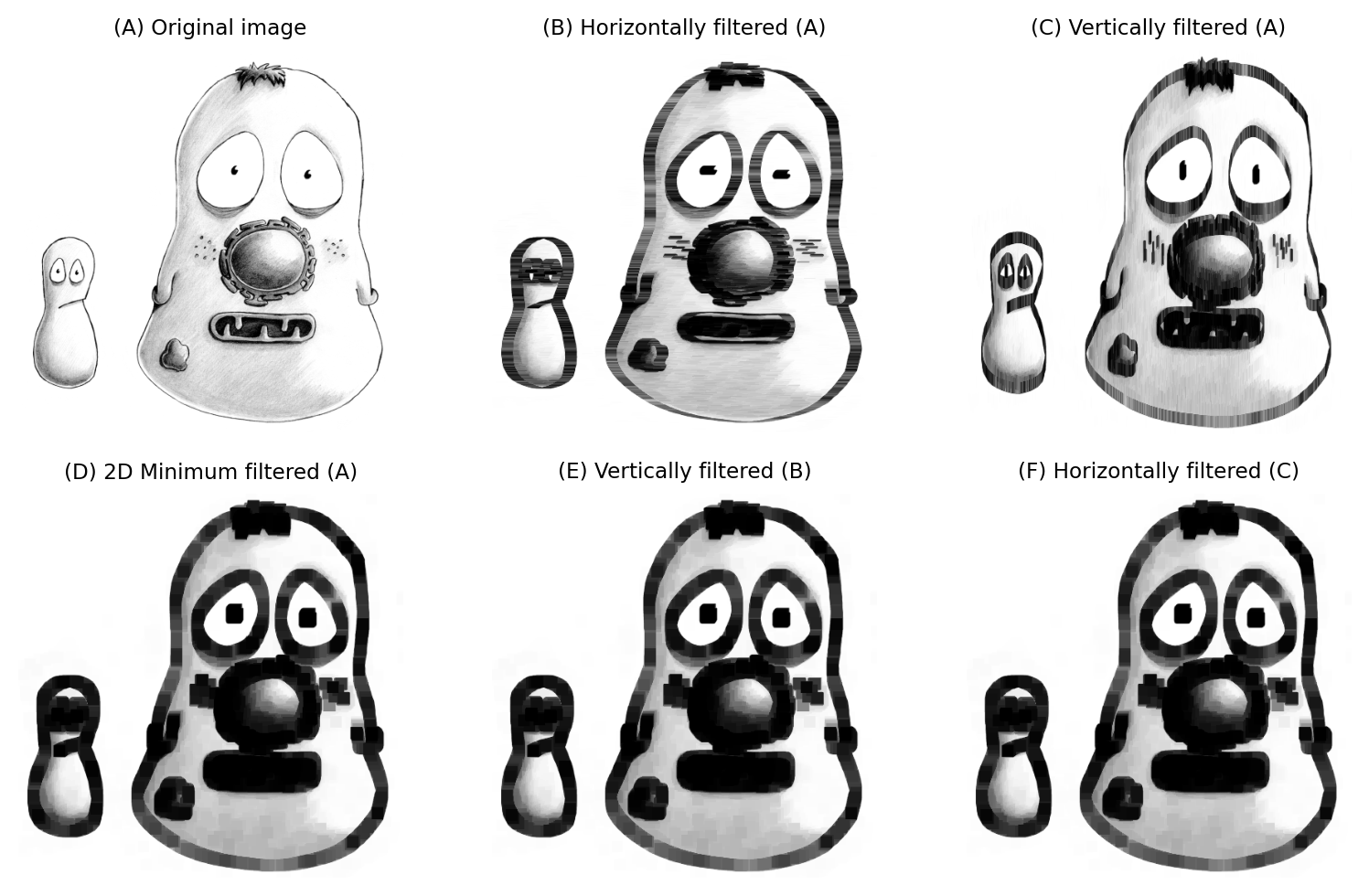
Fig. 131 A 15×15 minimum filter applied separably.#
Morphological operations#
Erosion, dilation, opening and closing can all be implemented using minimum and maximum nonlinear filters, so the above considerations apply. Morphological reconstruction can also work in nD. Therefore all the new operations and tricks derived from these methods (e.g. creating outlines, finding regional maxima) should work.
Thinning algorithms are often designed to work in 3D, although not usually higher dimensions.
Image transforms#
The distance and watershed transforms extend readily to 3D, but require a little caution.
One thing to look out for, especially with the distance transform, is whether pixel anisotropy is taken into consideration. If not, then the distance transform will not be capable of properly identifying the ‘nearest’ foreground or background pixel in calibrated units, but rather only in pixel units.
A cumbersome workaround may be to resize the image so that the pixels are isotropic, but that may make every other analysis step more complicated and/or require a huge amount more memory to store the image. A preferable approach is to try to find a distance transform implementation that incorporates pixel size information into its calculations.
Accelerating analysis#
One of the common themes of processing multidimensional images is performance.
Even though conceptually most of the image processing techniques we’ve discussed can be extended to 3D and beyond, it’s usually not easy to do from the programmer’s perspective. As someone who writes software, I can attest that I don’t tend to support more dimensions than I have to because extra dimensions make the task of coding, debugging and optimizing much, much harder.
‘Optimizing’ really matters because, as mentioned above, computational requirements can increase quickly and dramatically with multidimensional data. That doesn’t just mean the software itself needs to be optimized to run fast: the user plays a huge role in choosing what they ask the software to do. Keep in mind:
The most important performance consideration is the algorithm!
Before investing in a bigger computer to try to speed up a slow analysis workflow, look for ways to make it more efficient without compromising accuracy.
For example, do you really need to apply a 49×49×49 pixel filter to a large image, at a cost of 117,649 multiplications & additions for every pixel? If a separable filter can be used instead, you can shrink that figure to 147 (~0.12%). Perhaps the calculation can also be performed on a lower resolution image, saving even more effort.
Alternatively, if you find you’re applying large minimum or maximum filters to a binary image, perhaps you could instead use a distance transform for erosion and dilation.
When processing is slow, it’s worth trying to get the computer to work smarter, not harder.
Nevertheless, there comes a time when better hardware really can help – assuming the software can take advantage of it.
Most modern computers capable of image analysis contain multiple processors, which can do multiple things at the same time. Image analysis software that supports multiprocessing is able to use these processors to operate on different parts of the data simultaneously. It’s more work for the programmer, but better for the user.
The benefits of multiprocessing can be important, but still tend to be fairly modest. A typical desktop computer today could have between 2 and 8 processors (although particularly powerful machines can have more). However, doubling the numbers of processors doesn’t mean that the computation time is likely to be halved, because it’s hard for software to keep all the processors occupied. Tasks tend to depend upon one another, and so it’s common for one processor to have to lounge around while another processor is completing its part of the job. Our performance aspirations can also be thwarted by other bottlenecks, such as reading or writing images.
To see a dramatic improvement in image processing performance, we usually need to look into Graphics Processing Unit (GPUs), aka. graphics cards.
A GPU can’t do everything that a general-purpose processor can do, but it is very good at what it can do – which includes core operations like image filtering or matrix multiplication.
Programming for GPUs is rather specialized, but there are some tools to help. Robert Haase has worked extensively on using GPUs for multidimensional bioimage analysis – I highly recommend checking out CLIJ and clEsperanto for more details.