Noise#
Chapter outline
There are two main types of noise in fluorescence microscopy: photon noise & read noise
Photon noise is signal-dependent, varying throughout an image
Read noise is signal-independent, and depends upon the detector
Detecting more photons reduces the impact of both noise types
Introduction#
We could reasonably expect that a noise-free microscopy image should look pleasantly smooth, not least because the convolution with the PSF has a blurring effect that softens any sharp transitions. Yet in practice raw fluorescence microscopy images are not smooth. They are always, to a greater or lesser extent, corrupted by noise. This appears as a random ‘graininess’ throughout the image, which is often strong enough to obscure details.
This chapter considers the nature of the noisiness, where it comes from, and what can be done about it. Before starting, it may be helpful to know the one major lesson of this chapter for the working microscopist is simply:
Tip
If you want to reduce noise, you need to detect more photons
This general guidance applies in the overwhelming majority of cases when a good quality microscope is functioning properly. Nevertheless, it may be helpful to know a bit more detail about why – and what you might do if detecting more photons is not feasible.
Background#

Fig. 142 Illustration of the difference between a noisy image that we can record (A), and the noise-free image we would prefer (B). The ‘noise’ itself is what would be left over if we subtracted one from the other (C). The histogram in (D) resembles a normal (i.e. Gaussian) distribution and shows that the noise consists of positive and negative values, with a mean of 0.#
In general, we can assume that noise in fluorescence microscopy images has the following three characteristics, illustrated in Fig. 142:
Noise is random – For any pixel, the noise is a random positive or negative number added to the ‘true value’ the pixel should have.
Noise is independent at each pixel – The value of the noise at any pixel does not depend upon where the pixel is, or what the noise is at any other pixel.
Noise follows a particular distribution – Each noise value can be seen as a random variable drawn from a particular distribution. If we have enough noise values, their histogram would resemble a plot of the distribution [1].
There are many different possible noise distributions, but we only need to consider the Poisson and Gaussian cases. No matter which of these we have, the most interesting distribution parameter for us is the standard deviation. Assuming everything else stays the same, if the standard deviation of the noise is higher then the image looks worse (Fig. 143).
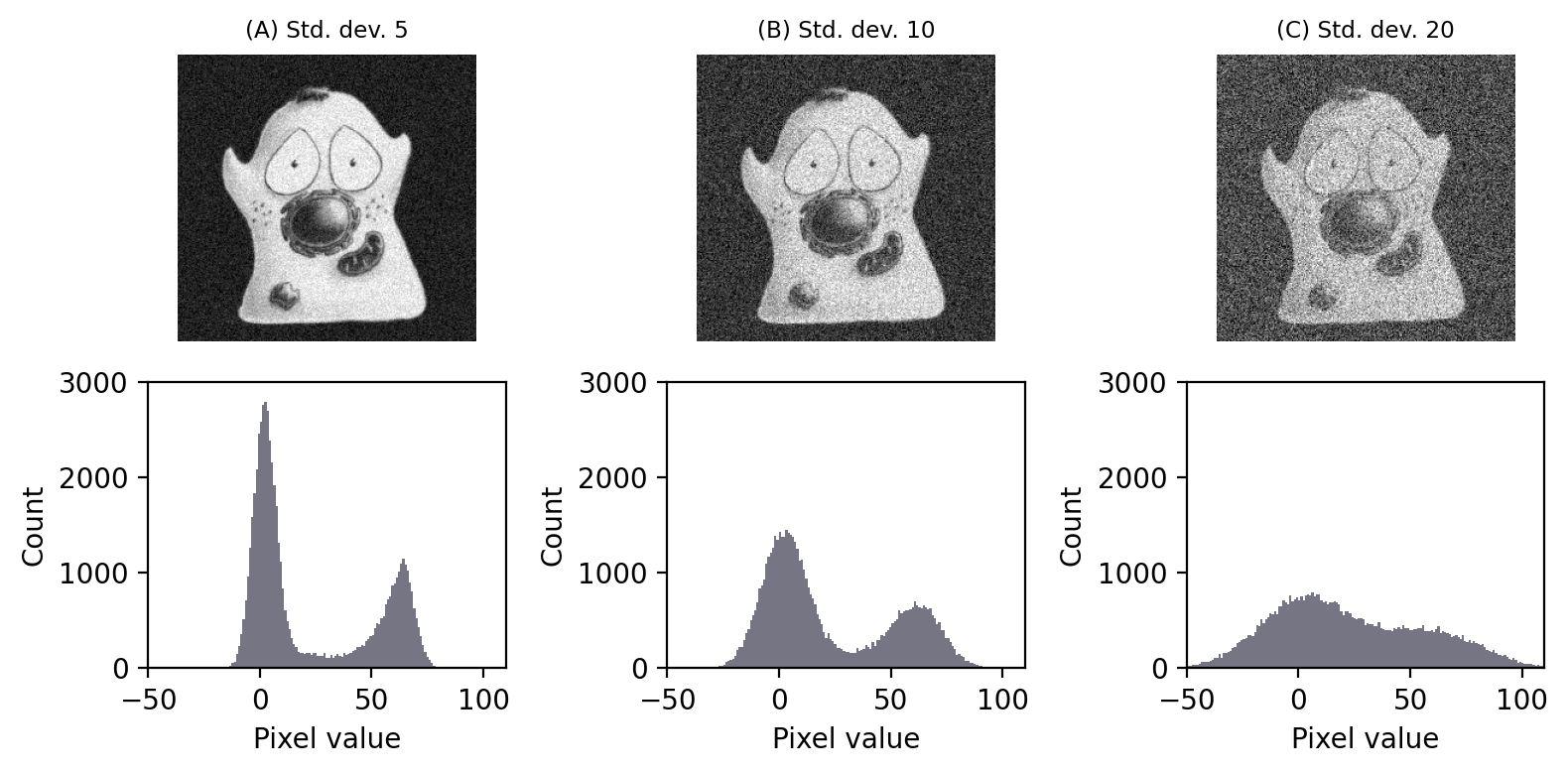
Fig. 143 Gaussian noise with different standard deviations added to an image. Noise with a higher standard deviation has a worse effect when added to an image. Its impact can be seen in the histogram, as the distribution of foreground and background pixels overlap more – which is problematic for things like thresholding.#
The reason we will consider two distributions is that there are two main types of noise for us to worry about:
Photon noise, from the emission (and detection) of the light itself. This follows a Poisson distribution, for which the standard deviation changes with the local image brightness.
Read noise, arising from inaccuracies in quantifying numbers of detected photons. This follows a Gaussian distribution, for which the standard deviation stays the same throughout the image.
Therefore the noise in the image is really the result of adding two [2] separate random components together. In other words, to get the value of any pixel \(P\) you need to calculate the sum of the ‘true’ (noise-free) value \(T\), a random photon noise value \(N_p\), and a random read noise value \(N_r\), i.e.
In this case, we have \(P\) in the image but we want \(T\). Unfortunately, we don’t know precisely what the random values \(N_p\) and \(N_r\) are.
Finally, some useful maths:
Suppose we add two random noisy values together. Both are independent and drawn from distributions (Gaussian or Poisson) with standard deviations \(\sigma_1\) and \(\sigma_2\). The result is a third random value, drawn from a distribution with a standard deviation \(\sqrt{\sigma_1^2 + \sigma_2^2}\).
If we multiply a noisy value from a distribution with a standard deviation \(\sigma_1\) by \(k\), the result is noise from a distribution with a standard deviation \(k\sigma_1\).
These are all my most important noise facts, upon which the rest of this chapter is built. We will begin with Gaussian noise because it’s easier to work with, found in many applications, and widely studied in the image processing literature. However, in most fluorescence images photon noise is the more important factor. Fortunately, there’s a close relationship between the Gaussian and Poisson noise – and it’s even possible to convert the latter to behave like the former.
Gaussian noise#
Gaussian noise is a common problem in fluorescence images acquired using a CCD camera (see Microscopes & detectors). It arises at the stage of quantifying the number of photons detected for each pixel. Quantifying photons is hard to do with complete precision, and the result is likely to be wrong by at least a few photons. This error is the read noise.
Read noise typically follows a Gaussian distribution and has a mean of zero: this implies there is an equal likelihood of over or underestimating the number of photons. Furthermore, according to the properties of Gaussian distributions, we should expect around ~68% of measurements to be ±1 standard deviation from the true, read-noise-free value. If a detector has a low read noise standard deviation, this is then a good thing: it means the error should be small.
Signal-to-Noise Ratio (SNR)#
Read noise is said to be signal independent: its standard deviation is constant, and does not depend upon how many photons are being quantified. However, the extent to which read noise is a problem probably does depend upon the number of photons. For example, if we have detected 20 photons, a noise standard deviation of 10 photons is huge; if we have detected 10 000 photons, it’s likely not so important.
A better way to assess the noisiness of an image is then the ratio of the interesting component of each pixel (called the signal, which is here what we would ideally detect in terms of photons) to the noise standard deviation, which is known as the Signal-to-Noise Ratio [3]:
Calculate the SNR in the following cases:
We detect an average of 10 photons, read noise standard deviation 1 photon
We detect an average of 100 photons, read noise standard deviation 10 photons
We detect an average of 1000 photons, read noise standard deviation 10 photons
For the purposes of this question, you should assume that read noise is the only noise present (ignore photon noise).
We detect an average of 10 photons, read noise std. dev. 1 photon: SNR = 10
We detect an average of 100 photons, read noise std. dev. 10 photons: SNR = 10
We detect an average of 1000 photons, read noise std. dev. 10 photons: SNR = 100
The noise causes us a similar degree of uncertainty in the first two cases. In the third case, the noise is likely to be less problematic: higher SNRs are good.
Exploring noise
I find the best way to learn about noise is by creating simulation images, and exploring their properties through making and testing predictions.
The figures in this chapter are generated using such simulations in Python. If you want to do something similar in ImageJ, you can add Gaussian noise with a fixed standard deviation to any image using .
If needed, you can create an empty 32-bit image with add noise to get an image containing nothing but noise.
Adding & averaging noisy images#
At the beginning of this chapter, I stated how to calculate the new standard deviation of the noise whenever two noisy pixels are added together:
Square the original noise standard deviation to get the variance for each pixel
Add the variances
Take the square root of the result
Suppose that we have two (independent) images with the same Gaussian noise standard deviation, let’s say 5. Applying this calculation, if we add the images together then the noise standard deviation of the resulting image is
The noise standard deviation of the resulting image is higher.
We might expect that the sum of two noisy image is therefore worse: we have increased the noise. However, we need to remember that the signal is also higher: in fact, it has been doubled (because we added two similar images).
If we want an output image with similar signal to the originals, we should average the corresponding pixel values instead of adding. In this case, averaging is the same as adding, except that we divide by two. When we do this, the noise standard deviation is also halved and becomes approximately 3.54 – i.e. it is lower than in either of the original two images.
This matters, because it implies that if we were to average two independent noisy images of the same scene with similar SNRs, we would get a result that contains less noise, i.e. a higher SNR.
But you shouldn’t just take my word for it. We can check that it really works by using a simulation. Fig. 144 demonstrates this, and has a very practical implication: noise reduction by averaging images creates a better peak separation in the histogram. This means it should usually give us an image that is more amenable to thresholding.
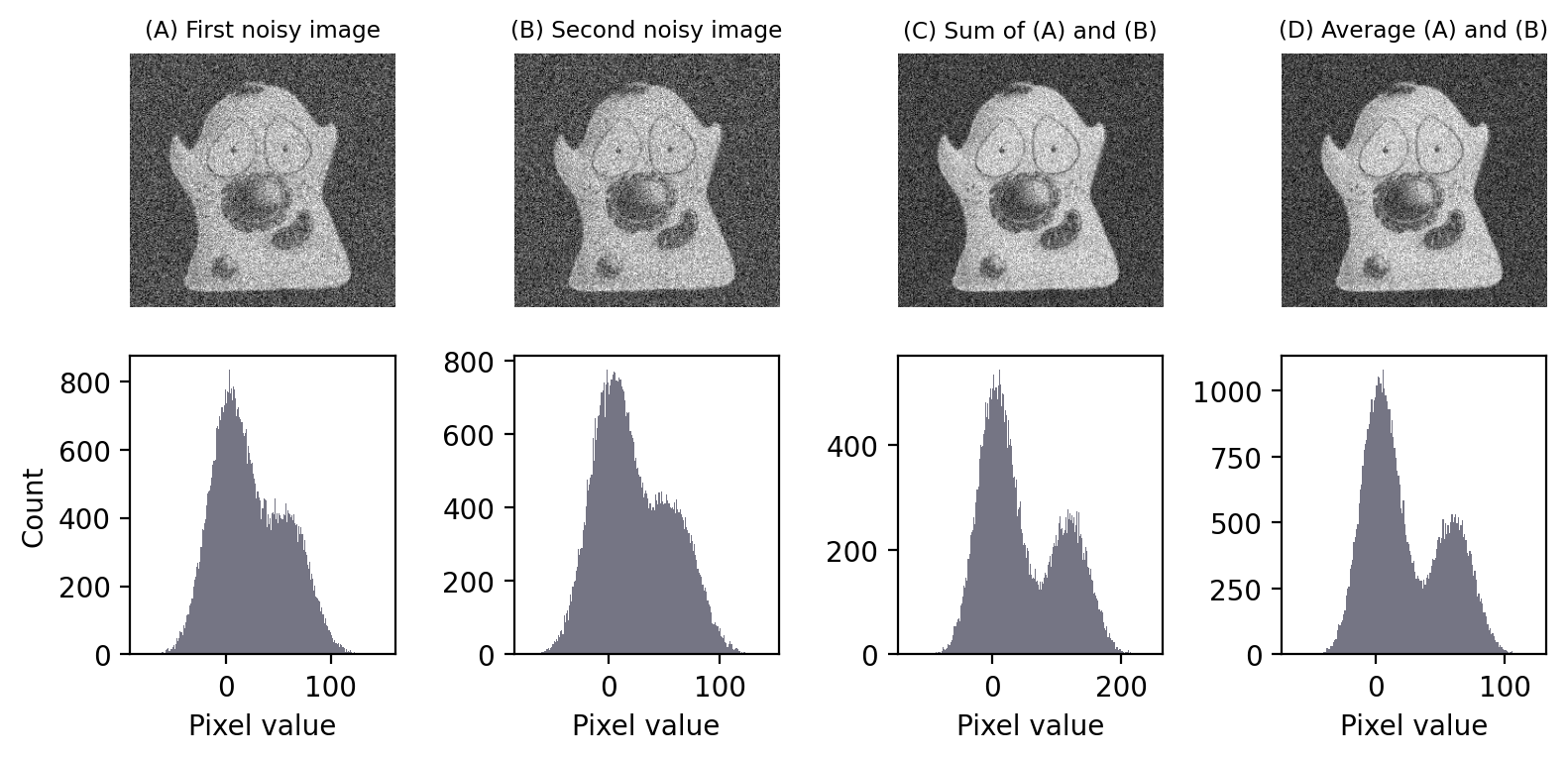
Fig. 144 Adding and averaging two independent images with Gaussian noise. Both adding and averaging give an image with an improved SNR, as can be seen in the improved separation between the histogram peaks.#
Adding & averaging within an image#
All this means that if can acquire the same image multiple times, then averaging our different images would give a result with reduced noise.
Of course, we don’t usually have multiple independent images of everything we might want to analyze. Instead, we just have one image. However, we can explore the idea by splitting a single image into two – provided we are willing to sacrifice some spatial resolution.
If we take the pixels from every second column of the image, we can extract these and combine them to form another image that looks like a squished version of the original. We can do the same process for all the columns we skipped – thereby giving us two squished images, one from the even-numbered columns and one from the odd-numbered columns.
You can see in Figure Fig. 145 that our squished images do look almost identical, because adjacent pixels usually do have very similar values – apart from the differences caused by noise. If we average these images together, these differences average out and we have another similar-looking image – but with reduced noise.
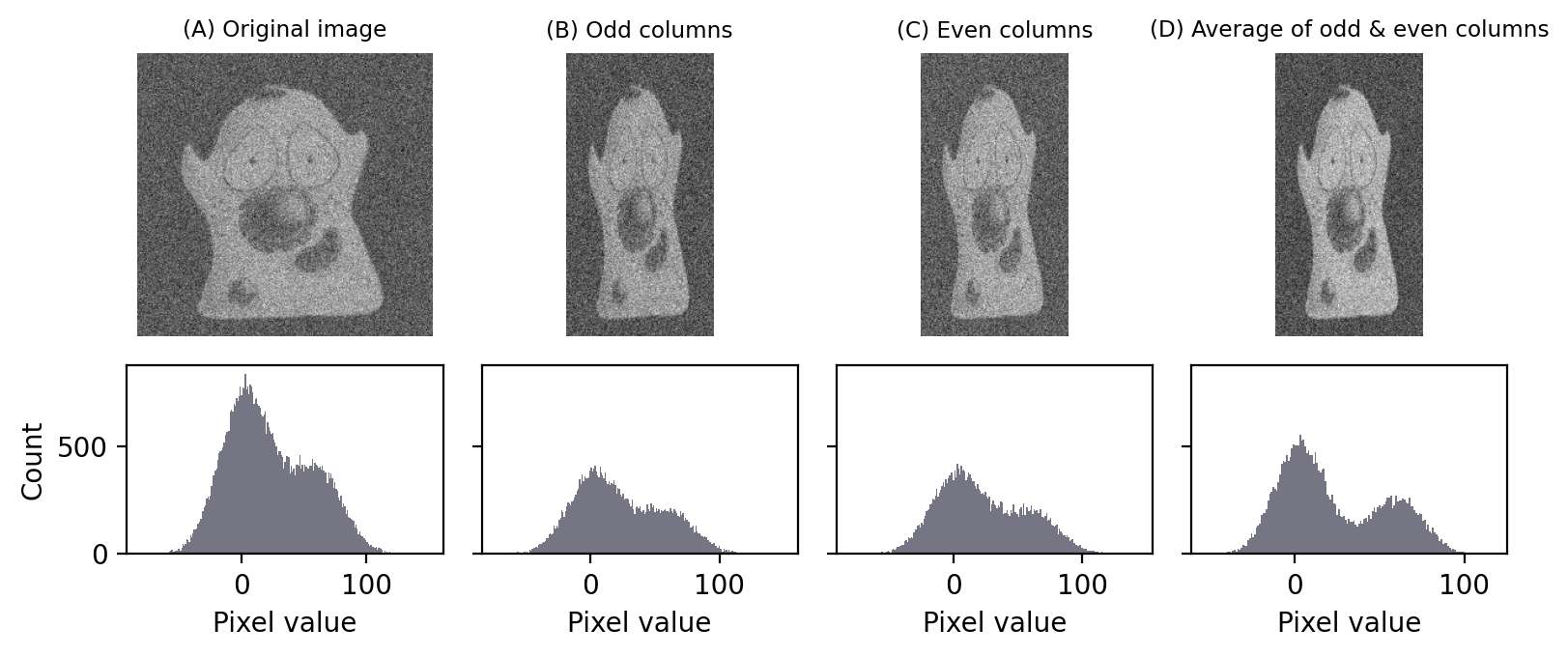
Fig. 145 Creating two images from one by taking even and odd-numbered columns. If we then average our two images, noise is reduced. The difference is subtle, but can be seen in the better separation of the peaks in the histogram.#
Of course, this trick has an obvious downside: the squishing is undesirable. Fortunately, we can avoid it simply by averaging adjacent columns but not splitting them into separate image. Then we can do the same with adjacent rows. And perhaps even adjacent diagonals, if we wish.
This is precisely the idea underlying our use of a 3×3 mean filter to reduce noise: we don’t have independent images to average, so we average within an image instead (Fig. 146).
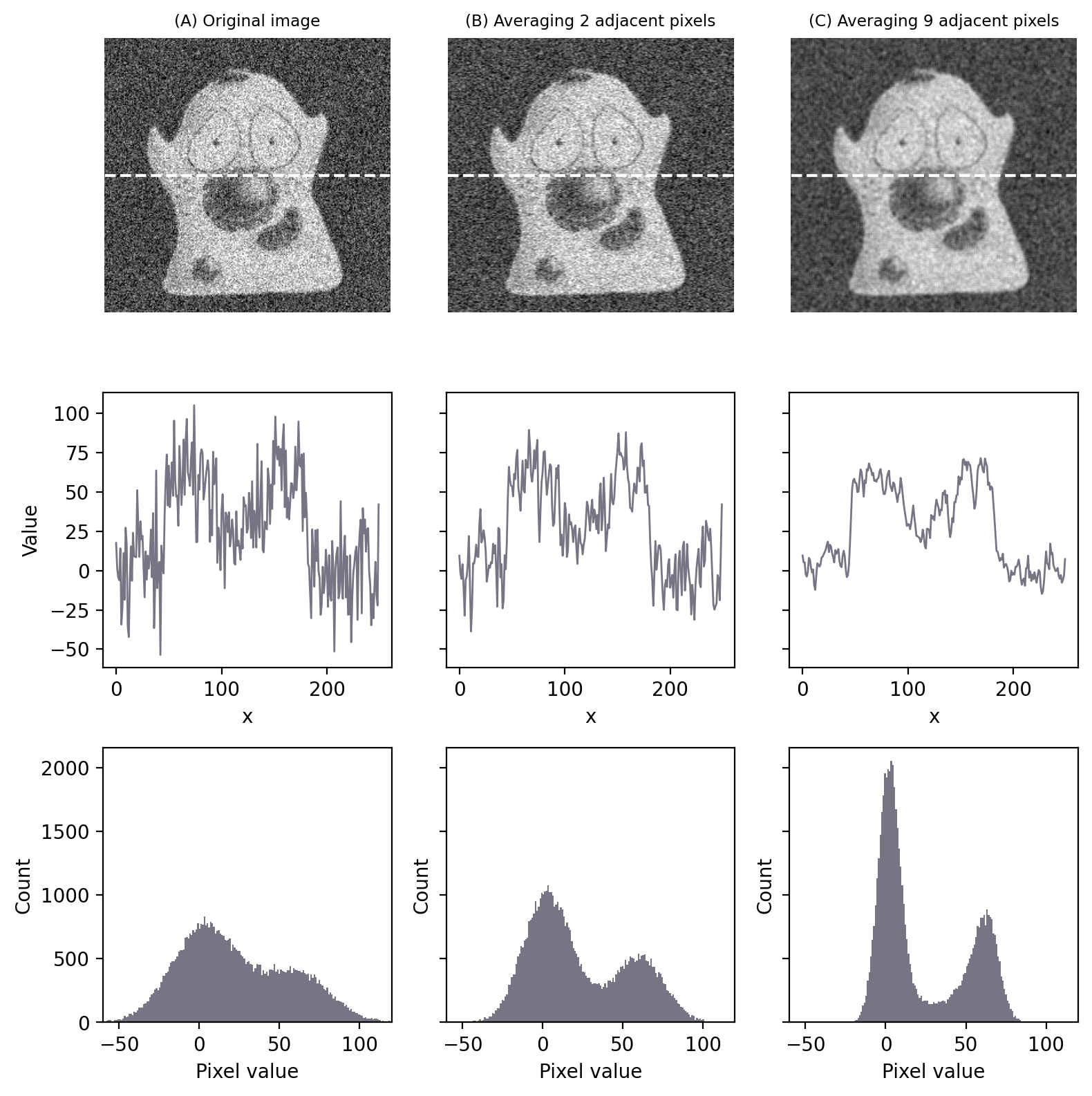
Fig. 146 Noise reduction by averaging adjacent pixels. Even though the overall appearance of the image has not changed much, the histograms indicate a much bigger separation of the foreground and background – meaning that thresholds are more likely to work well. In (C), the result is equivalent to applying a 3×3 mean filter.#
Hopefully this discussion helps build your intuition as to why filters are able to reduce Gaussian noise. In the next section, we’ll see how many of the same ideas apply to Poisson noise as well.
Poisson noise#
In 1898, Ladislaus Bortkiewicz published a book entitled The Law of Small Numbers. Among other things, it included a now-famous analysis of the number of soldiers in different corps of the Prussian cavalry who were killed by being kicked by a horse, measured over a 20-year period. Specifically, he showed that these numbers follows a Poisson distribution.
This distribution, introduced by Siméon Denis Poisson in 1838, gives the probability of an event happening a certain number of times, given that we know (1) the average rate at which it occurs, and (2) that all of its occurrences are independent. However, the usefulness of the Poisson distribution extends far beyond gruesome military analysis to many, quite different applications – including the probability of photon emission, which is itself inherently random.
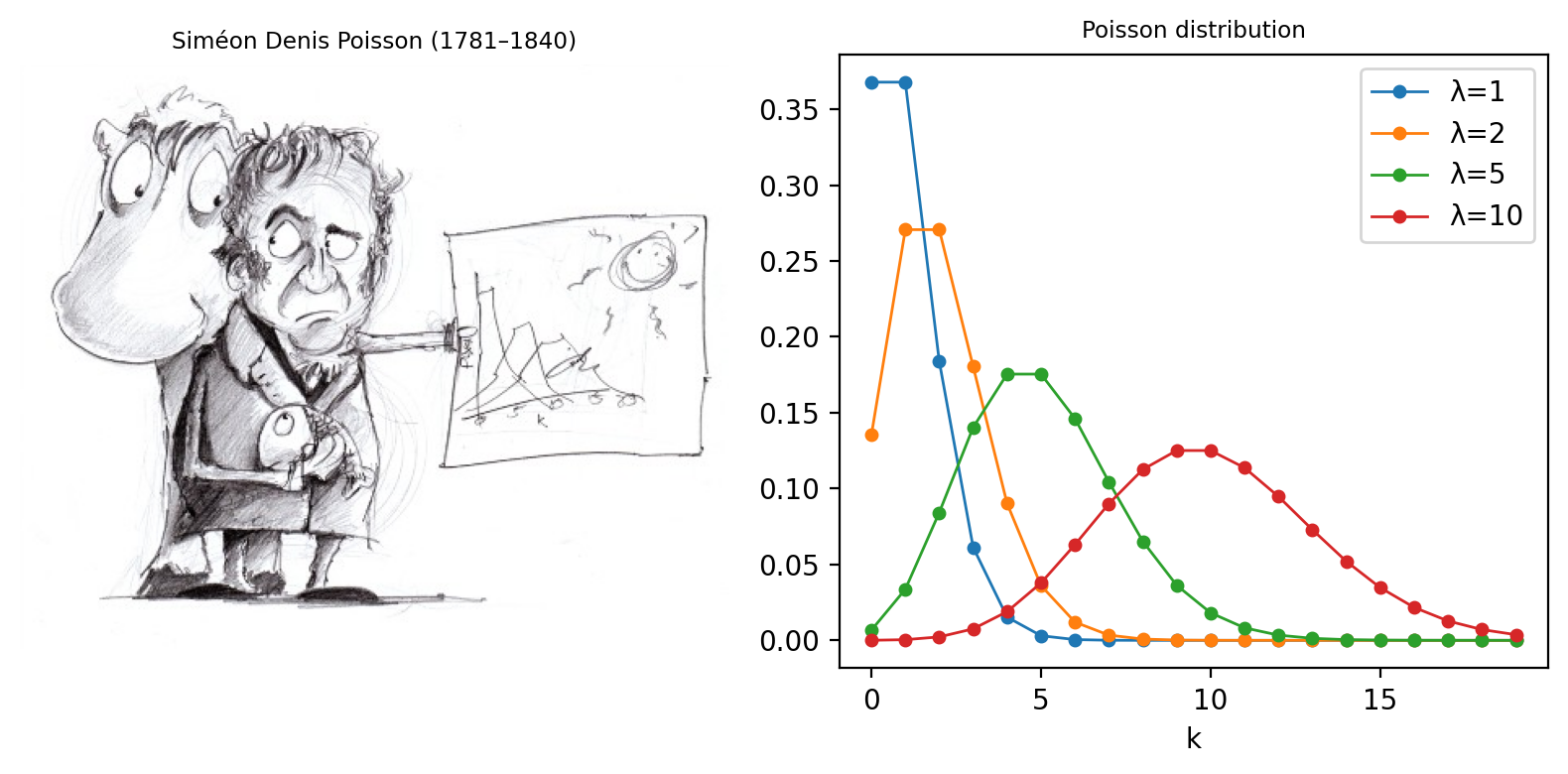
Fig. 147 Siméon Denis Poisson and his distribution. (A) Poisson is said to have been extremely clumsy and uncoordinated with his hands. This contributed to him giving up an apprenticeship as a surgeon and entering mathematics, where the problem was less debilitating – although apparently this meant his diagrams tended not to very well drawn (see https://mathshistory.st-andrews.ac.uk/Biographies/Poisson/). (B) The ‘Probability Mass Function’ of the Poisson distribution for several different values of λ. This allows one to see for any ‘true signal’ λ the probability of actually counting any actual value k. Although it’s more likely that one will count exactly k = λ than any other possible k, as λ increases the probability of getting precisely this value becomes smaller and smaller.#
Suppose that, on average, a single photon will be emitted from some part of a fluorescing sample within a particular time interval. The randomness entails that we cannot say for sure what will happen on any one occasion when we look; sometimes one photon will be emitted, sometimes none, sometimes two, occasionally even more. What we are really interested in, therefore, is not precisely how many photons are emitted, which varies every time we look, but rather the rate at which they would be emitted under fixed conditions, which is a constant. The difference between the number of photons actually emitted and the true rate of emission is the photon noise. The trouble is that keeping the conditions fixed might not be possible: leaving us with the problem of trying to figure out rates from single, noisy measurements.
Signal-dependent noise#
Clearly, since it’s a rate that we want, we could get that with more accuracy if we averaged many observations: just like with Gaussian noise, averaging reduces photon noise. Therefore, we can expect smoothing filters to work similarly for both noise types – and they do.
The primary distinction between the noise types, however, is that Poisson noise is signal-dependent, and does change according to the number of emitted (or detected) photons. Fortunately, the relationship is simple: if the rate of photon emission is \(\lambda\), the noise variance is also \(\lambda\), and the noise standard deviation is \(\sqrt{\lambda}\).
This is not really as unexpected as it might first seem (see Fig. 148). It can even be observed from a very close inspection of Fig. 149, in which the increased variability in the neuron causes its ghostly appearance even in an image that ought to consist (almost) exclusively of noise.

Fig. 148 ‘The standard deviation of photon noise is equal to the square root of the expected value.’ To understand this better, it may help to imagine a fisherman, fishing many times at the same location and under the same conditions. If he catches 10 fish on average, it would be quite reasonable to catch 7 or 13 on any one day – while 20 would be exceptional. If, however, he caught 100 on average, then it would be unexceptional if he caught 90 or 110 on a particular day, although catching only 10 would be strange (and presumably disappointing). Intuitively, the range of values that would be considered likely is related to the expected value. If nothing else, this imperfect analogy may at least help remember the name of the distribution that photon noise follows.#
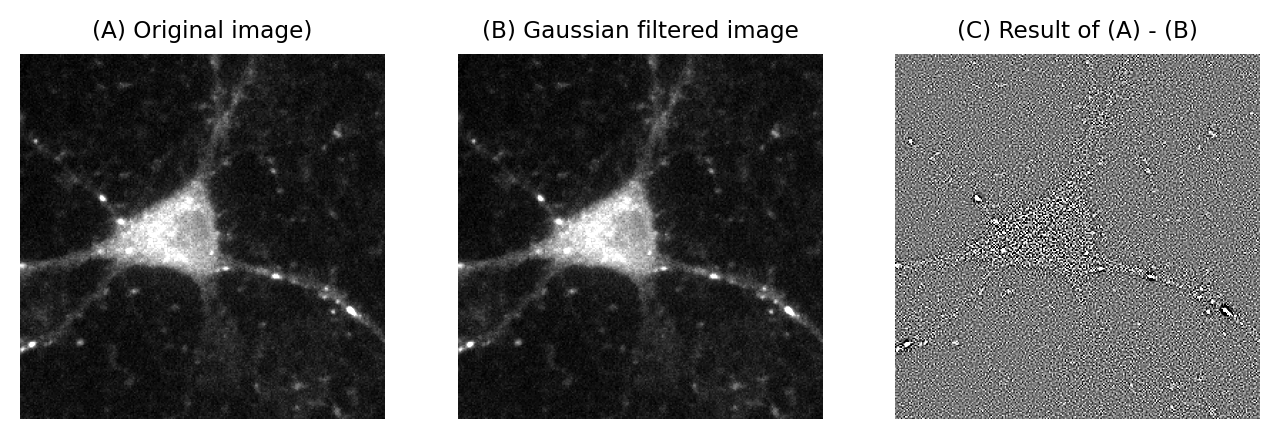
Fig. 149 A demonstration that Poisson noise changes throughout an image. (A) Part of a fluorescence microscopy image. (B) A Gaussian filtered version of (A) using a very small filter (\(\sigma\)=0.25). Gaussian filtering reduces the noise in an image by replacing each pixel with a weighted average of neighboring pixels (see Filters). (C) The difference between the original and filtered image contains the noise that the filtering removed. The brighter areas in the original image are still visible in this ‘noise image’ as regions of increased variability. This is partly an effect of Poisson noise having made the noise standard deviation larger in the brighter parts of the acquired image.#
The formula for the probability mass function of the Poisson distribution is:
where
\(\lambda\) is the mean rate of occurrence of the event (i.e. the noise-free photon emission rate we want)
\(k\) is an actual number of occurrences for which we want to compute the probability
\(k!\) is the factorial of \(k\) (i.e. \(k \times (k-1) \times (k-2) \times ... \times 1\))
So if you know that the rate of photon emission is 0.5, for example, you can put \(\lambda = 0.5\) into the equation and determine the probability of getting any particular (integer) value of \(k\) photons. Applying this, the probability of not detecting any photons (\(k = 0\)) is 0.6065, while the probability of detecting a single photon (\(k = 1\)) is \(0.3033\).
What we know for sure is that we can’t possibly detect 0.5 photons: we’ll get an integer value, not ‘part of a photon’.
Assuming the mean rate of photon emission is 1, use Equation (4) to calculate the probability of actually detecting 5 (which, at 5 times the true rate, would be an extremely inaccurate result). How common do you suppose it is to find pixels that are so noisy in the background region of a dark image?
The probability of detecting 5 photons is approximately 0.0031.
Although this is a very low probability, images contain so many pixels that one should expect to see such noisy values often. For example, in a rather dark and dull 512×512 pixel image in which the average photon emission rate is 1, we would expect 800 pixels to have a value of 5 – and two pixels even to have a value of 8. The presence of isolated bright or dark pixels therefore usually tells us very little indeed, and it is only by processing the image more carefully and looking at surrounding values that we can (sometimes) discount the possibility these are simply the result of noise.
The SNR for Poisson noise#
If the standard deviation of noise was the only thing that mattered, this would suggest that we are better not detecting much light: then the photon noise standard deviation is lower. But the SNR is a much more reliable guide. For noise that follows a Poisson distribution this is particularly easy to calculate. Substituting into the formula for the SNR (Equation (3)):
Therefore the SNR of photon noise is equal to the square root of the signal!
This means that as the average number of emitted (and thus detected) photons increases, so too does the SNR. More photons → a better SNR, directly leading to the assertion
Important
If you want to reduce photon noise, you need to detect more photons
We can visualize this using a simulation that displays how an image and its histogram change over time as more photons are detected.
This is really just the same as the insight that averaging reduces noise. Averaging and summing have the same effect, differing only by a constant scale factor.
Why relativity matters: a simple example
The SNR increases with the number of photons, even though the noise standard deviation increases too, because it’s really relative differences in the brightness in parts of the image that we are interested in. Absolute numbers usually are of very little importance – which is fortunate, since not all photons are detected.
Yet if you remain unconvinced that the noise standard deviation can get bigger while the situation gets better, the following specific example might help. Suppose the true signal for a pixel is 4 photons. Assuming the actual measured value is within one noise standard deviation of the proper result (which it will be, about 68% of the time), one expects it to be in the range 2–6. The true signal at another pixel is twice as strong – 8 photons – and, by the same argument, one expects to measure a value in the range 5–11. The ranges for both pixels overlap! With photon counts this low, even if one pixel has twice the value of another, we often cannot discern with confidence that the true, noise-free value for both pixels would be different at all.
On the other hand, suppose the true signal for the first pixel is 100 photons, so we measure something in the range of 90–110. The second pixel, still twice as bright, gives a measurement in the range 186–214. These ranges are larger, but crucially they are not even close to overlapping, so it’s very easy to tell the pixels apart. Thus the noise standard deviation alone is not a very good measure of how noisy an image is. The SNR is much more informative: the simple rule is that higher is better. Or, if that still does not feel right, you can turn it upside down and consider the noise-to-signal ratio (the relative noise), in which case lower is better (Fig. 150).
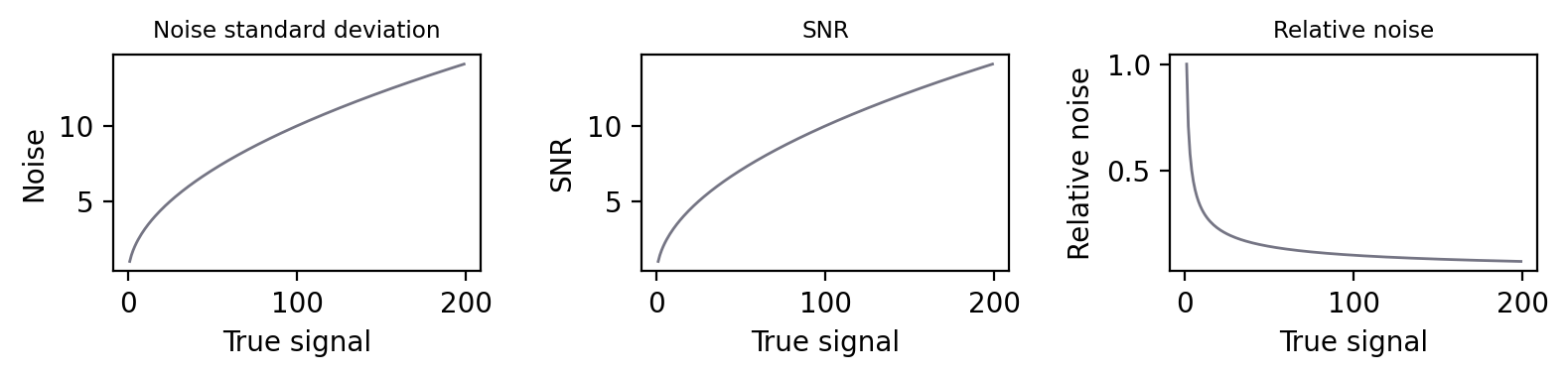
Fig. 150 For Poisson noise, the standard deviation increases with the square root of the signal. So does the SNR, with the result that plots (A) and (B) look identical. This improvement in SNR despite the growing noise occurs because the signal is increasing faster than the noise, and so the noise is relatively smaller. Plotting the relative noise (1/SNR) shows this effect (C).#
Poisson noise & detection#
So why should you care that photon noise is signal-dependent?
One reason is that it can make features of identical sizes and brightnesses easier or harder to detect in an image purely because of the local background. This is illustrated in Fig. 151.
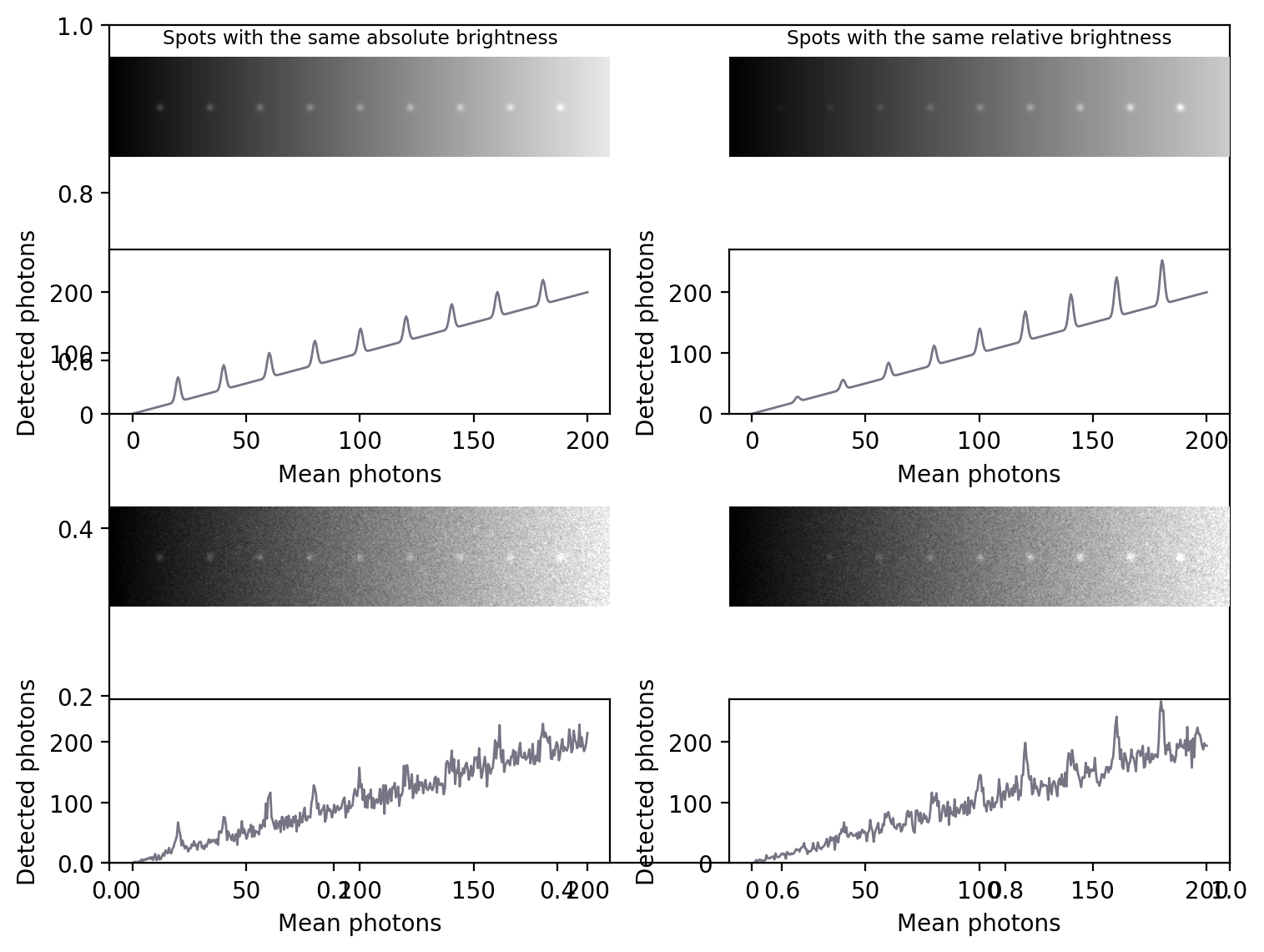
Fig. 151 The signal-dependence of Poisson noise affects how visible (and therefore detectable) structures are in an image. (A) Nine spots of the same absolute brightness are added to an image with a linearly increasing background (top) and Poisson noise is added (bottom). Because the noise variability becomes higher as the background increases, the spots in the darkest part of the image can be clearly seen in the profile but it’s more difficult to discern spots in the brighter part. (B) Spots of the same brightness relative to the background are added, along with Poisson noise. Because the noise is now relatively lower as the brightness increases, only the spots in the brightest part of the image can be seen, while those in the darker part are buried within the noise.#
In general, if we want to see a fluorescence increase of a fixed number of photons, this is easier to do if the background is very dark. But if the fluorescence increase is defined relative to the background, it will be much easier to identify if the background is high. Either way, when attempting to determine the number of any small structures in an image, for example, we need to remember that the numbers we will be able to detect will be affected by the background nearby. Therefore results obtained from bright and dark regions might not be directly comparable.
Open the images mystery_noise_1.tif and mystery_noise_2.tif in ImageJ.
Both are noisy, but in one the noise follows a Gaussian distribution (like read noise) and in the other it follows a Poisson distribution (like photon noise). Which is which?
![]()
The noise in mystery_noise_1.tif is Gaussian; the noise in mystery_noise_2.tif follows a Poisson distribution. Since there are reasonably flat regions within the cell and background, I would test this by drawing a ROI within each and measuring the standard deviations. Where these are similar, the noise is Gaussian; if there is a big difference, the noise is likely to be Poisson.
If no flat regions were available, I would try applying a gradient filter with the coefficients -1 1 0, and inspecting the results. Alternatively, I might try plotting a fluorescence profile or subtracting a very slightly smoothed version of each image.
Combining noise sources#
Combining our noise sources then, we can imagine an actual pixel value as being the sum of three values: the true rate of photon emission, the photon noise component, and the read noise component [4]. The first of these is what we want, while the latter two are random numbers that may be positive or negative.

Fig. 152 An illustration of how photon noise differs from read noise. When both are added to a signal (here, a series of steps in which the value doubles at each higher step), the relative importance of each depends upon the value of the signal. At low signal levels this doubling is very difficult to discern amidst either type of noise, and even more so when both noise components are present.#
This is illustrated in Fig. 152 using a simple 1D signal consisting of a series of steps. Random values are added to this to simulate photon and read noise. Whenever the signal is very low (indicating few photons), the variability in the photon noise is very low – but high relative to the signal (B)! This variability increases when the signal increases. However, in the read noise case (C), the variability is similar everywhere. When both noise types are combined in (D), the read noise dominates completely when there are few photons, but has very little impact whenever the signal increases. Photon noise has already made detecting relative differences in brightness difficult when there are few photons; with read noise, it can become hopeless.
Therefore overcoming read noise is critical for low-light imaging, and the choice of detector is extremely important (see Microscopes & detectors). But, where possible, detecting more photons is an extremely good thing anyway, since it helps to overcome both types of noise.
Other noise sources
Photon and read noise are the main sources of noise that need to be considered when designing and carrying out an experiment. One other source often mentioned in the literature is dark noise, which can be thought of as arising when a wayward electron causes the detector to register a photon even when there was not actually one there. In very low-light images, this lead to spurious bright pixels. However, dark noise is less likely to cause problems if many true photons are detected, and many detectors reduce its occurrence by cooling the sensor.
If the equipment is functioning properly, other noise sources could probably not be distinguished from these three. Nevertheless, brave souls who wish to know more may find a concise, highly informative, list of more than 40 sources of imprecision in The 39 steps: a cautionary tale of quantitative 3-D fluorescence microscopy by James Pawley (available online from various sources).
Suppose you have an image that does not contain much light, but has some isolated bright pixels.
Which kind of filter could you use to remove them? And is it safe to assume they are due to dark noise or something similar, or might the pixels correspond to actual bright structures?
A median filter is a popular choice for removing isolated bright pixels, although when using ImageJ I sometimes prefer because this only puts the median-filtered output in the image if the original value was really extreme (according to some user-defined threshold). This then preserves the independence of the noise at all other pixels – so it still behaves reliably and predictably like Poisson + Gaussian noise. We can reduce the remaining noise with a Gaussian filter if necessary.
Assuming that the size of a pixel is smaller than the PSF (which is usually the case in microscopy), it’s a good idea to remove these outliers. They cannot be real structures, because any real structure would have to extend over a region at least as large as the PSF. However if the pixel size is very large, then we may not be able to rule out that the ‘outliers’ are caused by some real, bright structures.
Finding photons#
There are various places from which the extra photons required to overcome noise might come. One is to simply acquire images more slowly, spending more time detecting light. If this is too harsh on the sample, it may be possible to record multiple images quickly. If there is little movement between exposures, these images could be added or averaged to get a similar effect (Fig. 153).
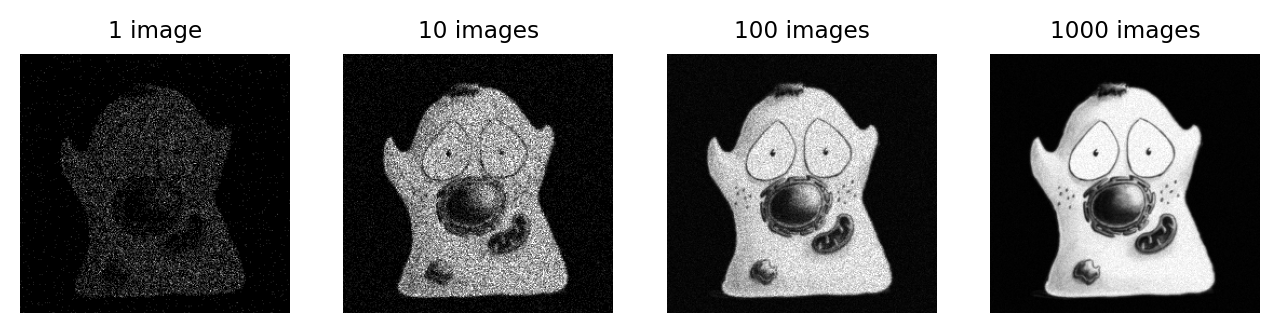
Fig. 153 The effect of adding (or averaging) multiple noisy images, each independent with a similar SNR.#
An alternative would be to increase the pixel size, so that each pixel incorporates photons from larger regions – although clearly this comes at a cost in spatial information. One way to do this is though binning.
However, noise cannot be completely eliminated during acquisition. Understanding its behavior, and especially how filters can reduce it, can help us cope with it during analysis.
Nyquist sampling & choosing a pixel size
Small pixels are needed to see detail, but also reduce the number of photons per pixel and thereby increase noise. However, Blur & the PSF has already argued that ultimately it’s not pixel size, but rather the PSF that limits spatial resolution – which suggests that there is a minimum pixel size below which nothing is gained, and the only result is that more noise is added.
This size can be determined based upon knowledge of the PSF and the Nyquist-Shannon sampling theorem (Fig. 154). Images acquired with this pixel size are said to be Nyquist sampled (although see Alvy Ray Smith’s epic A Biography of the Pixel for the case why credit for the sampling theorem really belongs to Vladimir Kotelnikov).
The easiest way I know to determine the corresponding pixel size for a given experiment is to use the online calculator provided by Scientific Volume Imaging at https://svi.nl/NyquistCalculator. You may need larger pixels to reduce noise or see a wider field of view, but you do not get anything extra by using smaller pixels.

Fig. 154 Harry Nyquist (1889-1975) and Claude Shannon (1916-2001), sampled using different pixel sizes. Their work is used when determining the pixel sizes needed to maximize the available information when acquiring images, which depends upon the size of the PSF.#