Archivos y formatos de archivo#
Outline del capítulo
Los archivos de imagen constan de valores de píxeles y metadatos
Algunos formatos de archivo son adecuados para datos para analizar, otros para datos solo para mostrar
Los metadatos esenciales para el análisis se pueden perder al guardarlos en un formato de archivo no científico
La compresión puede ser sin pérdidas o con pérdidas, con resultados diferentes
Los valores de píxeles originales se pueden perder mediante la compresión con pérdida, la conversión a RGB o la eliminación de dimensiones
Show code cell content
%load_ext autoreload
%autoreload 2
# Default imports
import sys
sys.path.append('../../../')
from helpers import *
from matplotlib import pyplot as plt
from myst_nb import glue
import numpy as np
from scipy import ndimage
Introducción#
Una de las formas más seguras de perder información al trabajar con imágenes es elegir mal el formato de archivo.
Existe una amplia gama de formatos de archivos que se utilizan para almacenar imágenes, pero no todos los formatos admiten todas las profundidades de bits, tipos y dimensiones necesarios para las imágenes científicas. Algunos formatos tienden a perder metadatos y otros comprometen los valores de píxeles mediante la compresión.
Para evitar estancarse en las complejidades del formato de archivo, quiero darte los mensajes principales de este capítulo desde el principio:
Trabajar con formatos de imagen
Manten siempre tus archivos de imagen originales, en su formato original.
Durante el análisis:
Utiliza software diseñado para datos científicos (es decir, no un editor general de fotografías)
Si necesitas guardar imágenes, utiliza el formato de archivo predeterminado para el software (por ejemplo, TIFF para ImageJ)
¡Comprueba todo! Asegúrate de poder volver a abrir la imagen después de guardarla y de que los valores de píxel, la información sobre el tamaño de píxel y las dimensiones se conserven exactamente.
Utiliza formatos de archivo de uso general (por ejemplo, PNG, JPEG) para figuras, presentaciones o sitios web, pero no para análisis posteriores.
Utiliza TIFF con precaución, ya que se puede utilizar tanto como formato científico adecuado para análisis, como formato de uso general adecuado sólo para visualización.
OME-TIFF suele ser una mejor alternativa a TIFF, ya que estandariza la forma en que se almacenan los metadatos.
Para ayudar a poner esto en práctica, Tabla 1 enumera algunos de los formatos de imagen más importantes que necesitas conocer al guardar imágenes tu mismo.
Formato |
Extensiones |
Uso principal |
Compresión |
Comentario |
|---|---|---|---|---|
TIFF |
.tif, .tiff |
Análisis, visualización (impresión) |
Ninguno, sin pérdidas, con pérdidas |
Formato de imagen muy general. |
OME-TIFF |
.ome.tif, .ome.tiff |
Análisis, visualización (imprimir) |
Ninguno, sin pérdidas, con pérdidas |
TIFF, con metadatos estandarizados para microscopía |
Zarr |
.zarr |
Análisis |
Ninguno, sin pérdidas, con pérdidas |
Formato emergente, ideal para grandes sets de datos, pero por el momento tiene soporte limitado |
PNG |
.png |
Visualización (web, impresión) |
Sin pérdidas |
Tamaños de archivos pequeños (más o menos) sin artefactos de compresión |
JPEG |
.jpg, .jpeg |
Pantalla (web) |
Con pérdida (normalmente) |
Tamaños de archivo pequeños, pero artefactos visibles |
El resto de este capítulo explica las ideas clave. A pesar de tener ya las conclusiones, espero que persistas en leer el resto de todos modos. Comprender más sobre los formatos de archivos puede ser de gran ayuda a la hora de elegir cómo guardar imágenes para diferentes propósitos y diagnosticar problemas cuando se han utilizado formatos incorrectos.
Contenido del archivo de imagen#
Un archivo de imagen almacenado en la computadora contiene dos elementos principales:
Valores de píxeles: los “números brutos” de la imagen
Metadatos: información adicional, como dimensiones, tipo de imagen, profundidad de bits, tamaños de píxeles y configuración del microscopio («datos sobre datos»)
Los valores de los píxeles son claramente importantes. Pero algunas partes de los metadatos son esenciales para que los datos de la imagen sean interpretables. Y si faltan metadatos como el tamaño de píxel o son incorrectos, las mediciones también pueden ser incorrectas. Por lo tanto, los archivos deben guardarse en formatos que preserven con precisión tanto los valores de píxeles como los metadatos para que sean adecuados para un análisis posterior.
Valores de píxeles y compresión#
Los valores de píxeles se representan mediante bytes. Como se describe en Tipos y profundidad de bits, una imagen de 8 bits usa 1 byte por píxel, una imagen de 16 bits usa 2 bytes por píxel y una imagen de 32 bits usa 4 bytes por píxel.
Sin embargo, la forma en que se almacenan estos bytes en el archivo de imagen puede depender de si se utiliza compresión. Hay tres opciones principales:
Sin compresión. Los bytes que representan los píxeles se almacenan directamente en el archivo. Esto significa que los valores de los píxeles se conservan exactamente, pero el archivo puede ser bastante grande.
Ejemplos: TIFF (sin comprimir), ICS/IDS
Compresión sin perdidas. Los bytes que representan los píxeles se almacenan mediante un algoritmo de compresión que (normalmente) hace que se requiera menos espacio de almacenamiento, al tiempo que permite reconstruir los valores originales exactamente mediante descompresión. En comparación con los datos sin comprimir, el tamaño del archivo que utiliza la compresión sin pérdidas es generalmente más pequeño, pero leer o escribir el archivo lleva más tiempo.
Ejemplos: TIFF (comprimido LZW), PNG, BMP, JPEG2000 (sin pérdidas)
Compresión con pérdida. Los bytes que representan los píxeles se almacenan utilizando un algoritmo de compresión que no tiene que poder reconstruir los valores originales exactamente. Esto puede dar como resultado archivos de tamaño dramáticamente más pequeños, pero con una pérdida de información en la imagen y, a menudo, artefactos visuales.
Ejemplos: TIFF (JPEG comprimido), JPEG, GIF, JPEG2000 (con pérdida)
Probablemente el formato de archivo más famoso que utiliza compresión con pérdida es JPEG.
La idea básica de la compresión JPEG es que una imagen se divide en bloques de 8x8 píxeles y se almacena una aproximación de los valores originales en lugar de los valores exactos en sí. Técnicamente, esta aproximación implica la “transformación de coseno discreto”; Para nuestros propósitos, es suficiente saber que los artefactos JPEG tienden a parecer cuadrados de 8x8 píxeles, cada uno de los cuales contiene patrones ondulados, que son más evidentes al acercar y/o aumentar el brillo y el contraste a un nivel extremo (Figura 53).
Show code cell content
# Load image
im = load_image('spooked.png')
# Re-save as a JPEG; we do need to set the JPEG compression quite low to make the artefacts obvious
from imageio import imread, imwrite
bytes_jpg = imwrite("<bytes>", im, plugin='pillow', format="JPEG", quality=20)
im_jpg = imread(bytes_jpg)
# Re-save as a PNG
bytes_png = imwrite("<bytes>", im, format="PNG")
im_png = imread(bytes_png)
# Re-save as an uncompressed TIFF
bytes_tif = imwrite("<bytes>", im, format="TIFF")
im_tif = imread(bytes_tif)
def add_rectangle(x, y, width, height, axes=None, linewidth=1, edgecolor='r', facecolor='none', **kwargs):
"""
Add rectangle to highlight selected region.
"""
import matplotlib.patches as patches
rect = patches.Rectangle((x, y), width, height, linewidth=1, edgecolor='r', facecolor='none')
if axes is None:
axes = plt.gca()
axes.add_patch(rect)
# Show image & details
fig = create_figure(figsize=(9, 5))
show_image(im_tif, pos=231, title=f'(A) TIFF uncompressed ({len(bytes_tif)/1024.0:.1f} KB)')
show_image(im_png, pos=232, title=f'(B) PNG compressed ({len(bytes_png)/1024.0:.1f} KB)')
show_image(im_jpg, pos=233, title=f'(C) JPEG compressed ({len(bytes_jpg)/1024.0:.1f} KB)')
r = 200
c = 200
w = 50
h = 38
show_image(im_tif[r:r+h, c:c+w], pos=234)
show_image(im_png[r:r+h, c:c+w], pos=235)
show_image(im_jpg[r:r+h, c:c+w], pos=236)
# Add rectangle to highlight detail area
for ax in fig.axes:
add_rectangle(c, r, w, h, axes=ax)
plt.tight_layout()
glue_fig('fig_files_lossy', fig)

Figura 53 Ejemplos de imágenes guardadas con (A) sin compresión, (B) compresión sin pérdida y (C) compresión JPEG con pérdida. Los valores de píxeles de (A) y (B) son idénticos. La imagen (C) es similar, pero al hacer zoom en una región detallada se revelan artefactos JPEG característicos.#
Calidad de compresión
La compresión con pérdida a menudo se puede variar con una configuración de «calidad de compresión». Para un JPEG con una configuración de alta calidad, es probable que los artefactos de 8x8 sean mucho menos obvios de lo que aparecen en Figura 53, aunque los valores de píxeles aún están modificados. . Por lo tanto, es una buena idea utilizar también statistics & histograms para verificar cambios de píxeles.
Teniendo en cuenta la importancia de preservar los valores de los píxeles, la regla sencilla es la siguiente:
Advertencia
¡La compresión con pérdida es mala para el análisis!
En caso de duda, no utilices compresión con pérdida cuando trabajes con imágenes científicas.
La elección entre «sin compresión» y «compresión sin pérdidas» es una cuestión de preferencia, dependiendo de si es más importante para ti ahorrar espacio en el disco o abrir las imágenes rápidamente. La compatibilidad también es una consideración si deseas abrir las imágenes en diferentes programas: no todos los tipos de compresión son compatibles con todos los programas. Así que es mejor comprobar esto antes de guardar muchas imágenes en un formato que quizás no puedas leer en ningún otro lugar.
¿Cómo sé si un archivo ha sido comprimido?
Una manera fácil de identificar si una imagen se ha comprimido con pérdida es mirar la extensión del archivo y verificar si coincide con un formato que utiliza compresión con pérdida (por ejemplo, .jpeg). Fácil, pero no siempre exitoso.
Una razón es que algunos formatos de archivo admiten compresión con y sin pérdida. Por ejemplo, tanto JPEG como JPEG2000 (¡no es lo mismo!) generalmente se usan con compresión con pérdida, pero ambos podrían usarse también para compresión sin pérdida. A menos que tengas pruebas de lo contrario, si ves un archivo con extensión .jpg, .jpeg, .jp2, entonces es mejor asumir que se ha utilizado compresión con pérdida.
Las imágenes TIFF son particularmente complicadas. Una imagen TIFF podría contener datos sin comprimir o datos comprimidos utilizando una variedad de métodos diferentes, tanto sin pérdida como con pérdida, incluyendo JPEG. Para determinar si una imagen TIFF ha utilizado compresión con pérdida, es posible que se necesite más trabajo de detective (por ejemplo, hacer zoom y buscar artefactos, comparar estadísticas de píxeles con el archivo de datos original o usar software para verificar metadatos).
Se necesitan aproximadamente 1 MB para almacenar (1.000.000 bytes) una imagen sin comprimir de 8 bits con 1.000.000 de píxeles.
¿Cuánta memoria se necesita para almacenar una imagen de 16 bits con la misma cantidad de píxeles?
Puedes ignorar el poco espacio adicional necesario para almacenar los metadatos asociados.
2MB.
8 bits corresponden a 1 byte, por lo que 16 bits corresponden a 2 bytes. Multiplicamos la cantidad de bytes por píxel por la cantidad de píxeles para obtener el tamaño mínimo requerido para almacenar la imagen sin comprimir.
Supongamos que tienes una imagen original en formato TIFF (sin compresión). Primero, lo guardas como JPEG (compresión con pérdida) para reducir el tamaño del archivo, luego lo cierras y desechas el TIFF.
Al escuchar que JPEG es malo, vuelves a abrir la imagen y la guardas como TIFF una vez más (sin compresión), desechando el JPEG. ¿Cómo se ve tu imagen TIFF final y cuál es tu tamaño de archivo?
La imagen final se verá exactamente igual a la versión JPEG, ¡pero con el mismo tamaño de archivo que el TIFF original! Como tal, tiene «lo peor de ambos mundos».
Metadatos centrales#
Los valores de píxeles se representan como un [flujo de bits: unos y ceros] (chap_bit_depths). Algunas piezas centrales de metadatos deben almacenarse junto con estos bits para interpretarlos como una imagen, como las dimensiones, la profundidad de bits y el tipo. Si esta información falta, o es incorrecta, entonces la imagen generalmente no se puede leer o se ve extraña de alguna manera (Figura 54).
Show code cell content
# Load image
im = load_image('happy_cell.tif')
assert im.ndim == 2
# Store the 'true' shape & byte array for the pixel values
shape = im.shape
raw_bytes = im.tobytes()
raw_dtype = im.dtype
# Generate new images from the raw byte arrays... some right, some wrong
im_correct = np.frombuffer(raw_bytes, dtype=raw_dtype).reshape(shape)
im_wrong_shape = np.frombuffer(raw_bytes, dtype=raw_dtype).reshape(shape[::-1])
im_wrong_type = np.frombuffer(raw_bytes, dtype=np.uint32).reshape(shape)
im_wrong_bits = np.frombuffer(raw_bytes, dtype=np.uint8).reshape([s * 2 for s in shape])
fig = create_figure(figsize=(12, 6))
show_image(im_correct, pos=141, title='Correct metadata')
show_image(im_wrong_shape, pos=142, title='Wrong shape\n(Width & height swapped)')
show_image(im_wrong_type, pos=143, title=f'Wrong type\n({im_wrong_type.dtype}, not {raw_dtype})')
show_image(im_wrong_bits, pos=144, title=f'Wrong type & bit-depth\n({im_wrong_bits.dtype}, not {raw_dtype})')
glue_fig('fig_files_core_metadata', fig)
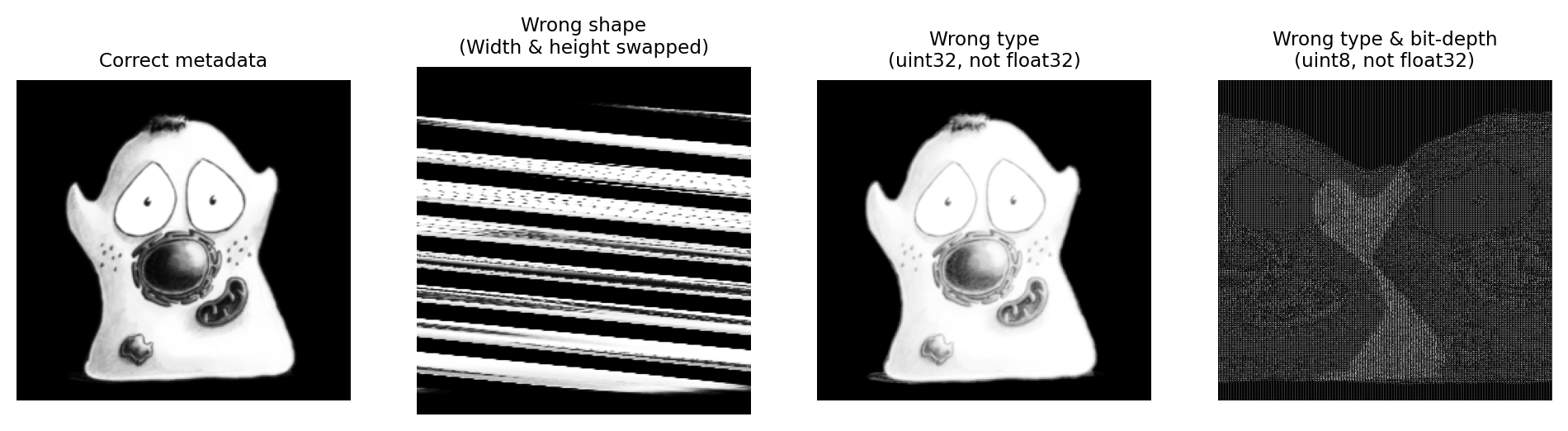
Figura 54 Algunos ejemplos de metadatos principales leídos correcta o incorrectamente.#
La mayoría de las veces, no necesitamos preocuparnos por esto porque todos los formatos de archivos de imagen almacenan esta información básica y el software utilizado para abrir la imagen normalmente la interpreta correctamente.
Pero no es extraño que algún formato nuevo y elegante almacene los metadatos centrales de una manera que no pueda ser leída e interpretada adecuadamente por otro software. Si intentas abrir tus imágenes y descubres que se ven muy extrañas, debes tener en cuenta que podría haber un problema de metadatos y que podrías necesitar comunicarte con el diseñador del software para descubrir qué salió mal.
Más comúnmente, la elección del formato de archivo afecta el tipo de imagen que se puede almacenar. Por ejemplo, las imágenes PNG o JPEG se limitan a datos enteros 2D, opcionalmente con 1, 3 o 4 canales; no admiten (por ejemplo) imágenes de punto flotante de 32 bits, pilas z o series temporales. Por lo tanto, guardar una imagen de punto flotante 5D como JPEG o PNG implica inherentemente convertir el tipo de imagen y descartar información.
Metadatos adicionales#
La pieza más importante de metadatos “no básicos” es el tamaño de píxel. A diferencia de los metadatos principales, no es necesario que un formato de archivo conserve el tamaño de píxel para que una imagen se abra y parezca «correcta».
Esto es un problema porque si el tamaño de píxel es incorrecto o falta, sigue siendo posible realizar mediciones de longitud, área o volumen dentro de una imagen, pero es probable que estas mediciones sean incorrectas.
En microscopía, el tamaño de píxel normalmente se representa como un valor en µm/píxel. Al guardar en algunos formatos de archivo (por ejemplo, JPEG y PNG) se tiende a perder información sobre el tamaño de los píxeles. Otros (por ejemplo, TIFF) podrían conservar el tamaño de píxel, podrían perderlo o podrían convertirlo en algo completamente distinto.
Esto debería sonar extraño, aterrador e indignante. Perder información sobre el tamaño de los píxeles es una cosa, pero ¿¡¿por qué un software astuto simplemente cambiaría el valor a otra cosa??!?
Para explicar esto, debemos recordar que la mayoría de las imágenes no están destinadas al análisis. La mayoría están destinadas únicamente a la exhibición. Y, a efectos de visualización, el tamaño puede tener un significado diferente.
Muchos investigadores ya se encuentran con esto cuando tratan de publicar artículos. Las revistas a menudo exigen que las figuras se envíen con una resolución suficientemente alta para su impresión, con la resolución definida en términos de puntos por pulgada (dpi). Por ejemplo, se podría solicitar una imagen de al menos 300 ppp. Si debe imprimirse en un tamaño de 2 x 2 pulgadas, entonces debe tener al menos 600 x 600 píxeles.
Para una imagen con una resolución de 300 ppp, se podría argumentar que un solo píxel tiene un tamaño de 1/300 pulgadas. En este caso, el tamaño está relacionado con la visualización. No importa lo que represente la imagen (podría ser una célula, una persona, un edificio, una galaxia) ni nos dice nada sobre su escala. En este caso, el tamaño de píxel sólo nos dice cómo se debe mostrar la imagen.
Cuando se trata de imágenes TIFF, el tamaño de píxel para ciencia o el tamaño de píxel para visualización (es decir, ppp) pueden almacenarse exactamente en la misma parte del archivo. Por lo tanto, lo que realmente significa este valor depende completamente de qué software escribió la imagen y si estaba más relacionado con el análisis o la visualización.
Por esta razón:
Advertencia
¡Siempre verifica los valores de tamaño de píxel!
La forma de hacerlo dependerá del software que estés utilizando: cada uno puede mostrar información sobre el tamaño de los píxeles en un lugar diferente. Pero una regla universal es utilizar todo el conocimiento que tengas sobre lo que esté en tus imágenes.
Por ejemplo, supongamos que tienes una imagen de células. Una búsqueda rápida en Internet puede revelar el diámetro típico de un núcleo (quizás 5-20 μm). Por lo tanto, podrías dedicar unos minutos a medir algunos diámetros de núcleos para ver si están cerca de este valor. Si es así, no prueba que el tamaño de píxel sea correcto, pero sí da cierta confianza adicional; si el valor está lejos de lo esperado, entonces es una advertencia de que el tamaño de píxel es incorrecto.
Elegir formatos de archivo#
La elección correcta del formato de archivo depende de cuándo guardes la imagen y de lo que desees hacer con ella. A continuación se describen tres escenarios principales.
Durante la adquisición#
La regla general es
Guardar imágenes durante la adquisición
Utiliza el formato de archivo predeterminado para tu microscopio y software de adquisición.
La razón es que el formato del fabricante debe preservar toda la información y los metadatos. A menudo, el software de adquisición permite guardar los datos de alguna otra manera, pero eso puede ser arriesgado. Existe una gran posibilidad de que se pierdan al menos algunos metadatos. A veces, la exportación alternativa puede hacer cosas aún peores, como convertir los datos a RGB.
La desventaja de esto es que los formatos de microscopía suelen ser poco comunes en el resto del mundo, lo que significa que tus imágenes pueden ser difíciles de abrir en otro software.
Afortunadamente, existe un magnífico proyecto de código abierto para ayudar con esto: Bio-Formats.
Bio-Formats permite leer una amplia gama de formatos diferentes mediante muchas aplicaciones de software diferentes. Ya está disponible en Fiji y QuPath de forma predeterminada, o se puede instalar como complemento para ImageJ. Aunque está escrito en Java, los bioformatos también se pueden utilizar en algunas aplicaciones de Python.
Si tienes la mala suerte de que Bio-Formats no admita el formato nativo de tu microscopio, es posible que debas exportarlo en un formato diferente para usarlo en otro lugar. Pero si haces esto, es mejor conservar una copia de los datos originales de todos modos, de modo que siempre puedas consultarlos utilizando el software de adquisición original para comprobar qué (si es que se ha perdido algo) se pudo haber perdido en la exportación.
Durante el análisis#
Si deseas guardar una imagen durante el análisis, la regla es
Guardar imágenes durante el análisis
Utiliza el formato de archivo predeterminado para el software de análisis que estés utilizando, o OME-TIFF
Al igual que la regla de adquisición, la idea es que esto generalmente preserve tantos metadatos como sea posible.
Para ImageJ, el formato predeterminado es una imagen TIFF sin comprimir. Esto admite imágenes de 8, 16 y 32 bits con hasta 5 dimensiones, comprimiendo los metadatos clave requeridos por ImageJ (por ejemplo, tamaño de píxel) en uno de los campos TIFF. Toda esta información debería estar disponible si abres la imagen nuevamente en ImageJ o Fiji, aunque no necesariamente se conserva si abres el TIFF en otro software, que puede no saber cómo interpretar los metadatos de ImageJ. Entonces, si esto es importante para ti, deberás comprobarlo.
Sin embargo, esta podría no ser la mejor opción si deseas continuar trabajando con tu imagen en un software diferente. En ese caso, puede ser necesario explorar un poco para ver qué formatos permiten guardar metadatos de una manera que tus aplicaciones de software preferidas los reconozcan.
Si estás utilizando software que incorpora bioformatos, la mejor opción probablemente sea OME-TIFF. Bio-Formats puede leer y escribir imágenes OME-TIFF, que tiene un estándar muy bien definido para almacenar metadatos (desarrollado por el grupo detrás de Bio-Formats). Esto abre más posibilidades, como escribir archivos TIFF que incluyan compresión sin pérdidas o con pérdidas. OME-TIFF también puede contener muchos más metadatos que un ImageJ TIFF, incluidos elementos como la posición de la platina del microscopio, la potencia del láser, etc.
Para mostrar#
Cuando se trata de mostrar imágenes, normalmente solo necesitamos un formato que admita imágenes RGB. Dado que no usaremos la imagen para análisis posteriores, no necesitamos preservar el tamaño de píxel y no necesariamente tenemos que evitar artefactos de compresión. Mis formatos preferidos personales para diferentes escenarios son:
Figura de la revista: TIFF.
A menudo, la revista solicita esto de todos modos. Aunque no esté convencido, siempre tiene sentido.Presentación: PNG.
El tamaño del archivo no suele ser un problema y PNG proporciona algo de compresión sin introducir artefactos.Sitio web: JPEG o PNG,
JPEG (generalmente) porque los tamaños de archivo más pequeños significan que el sitio web puede cargarse más rápido (y consumir menos datos). Pero se recomienda PNG para imágenes que contienen pocos colores, incluyendo la mayoría de las imágenes «artificiales», como dibujos, cuadros de diálogo o logotipos. Los artefactos JPEG pueden verse especialmente feos en tales casos, mientras que PNG puede comprimirlos muy bien.
Show code cell content
fig = create_figure(figsize=(8, 4))
show_image('images/vb_scientist_orig.png', title='(A) Vector image or bitmap?', pos=131)
show_image('images/vb_scientist_vector_labelled.png', title='(B) Enlargement of vector image)', pos=132)
show_image('images/vb_scientist_bitmap_labelled.png', title='(C) Enlargement of bitmap)', pos=133)
glue_fig('fig_files_vector_bitmap', fig)
Creando figuras para publicación.
Preparar figuras para su publicación puede ser un proceso desconcertante. Para empezar, es necesario hacer otra distinción entre tipos de imágenes, una de las cuales no se ha comentado aquí hasta ahora:
Mapas de bits. Estos se componen de píxeles individuales: p.e. fotografías, o todas las imágenes de microscopía que nos conciernen aquí.
Imágenes vectoriales. Estos se componen de líneas, curvas, formas o texto. Las instrucciones necesarias para dibujar la imagen (es decir, coordenadas, ecuaciones, fuentes) se almacenan en lugar de píxeles, y luego la imagen se recrea a partir de estas instrucciones cuando es necesario.
El resto de partes de este manual se concentra en imágenes de mapa de bits. Las imágenes vectoriales son bastante diferentes.
Si escalas una imagen de mapa de bits 2D duplicando su ancho y alto, esta contendrá cuatro veces más píxeles. Es necesario hacer conjeturas sobre cómo completar correctamente la información adicional (que es el problema de interpolación), y el resultado generalmente parece menos nítido que el original. Pero si duplicas el tamaño de una imagen vectorial, solo es cuestión de actualizar las matemáticas necesarias para dibujar la imagen adecuadamente, y el resultado se verá tan nítido como el original.
Por lo tanto, las imágenes vectoriales son mejores para cosas como diagramas, histogramas, gráficos y figuras, porque se puede cambiar su tamaño libremente y seguir teniendo buen aspecto. Además, a menudo tienen tamaños de archivo pequeños porque sólo es necesario conservar unas pocas instrucciones para volver a dibujar la imagen, mientras que es posible que se requiera una gran cantidad de píxeles para almacenar un texto suficientemente bonito y nítido en un mapa de bits. Pero los mapas de bits son necesarios para las imágenes formadas a partir de la detección de luz, que no pueden reducirse a unas pocas ecuaciones e instrucciones simples.
Finalmente, algunos formatos de archivo versátiles, como PDF o EPS, pueden almacenar ambos tipos de imágenes: tal vez un mapa de bits con algunas anotaciones de texto encima. Si incluyes texto o diagramas, estos formatos suelen ser los mejores. Pero si sólo tienes mapas de bits sin anotaciones de ningún tipo, entonces TIFF es probablemente el formato de archivo más común para crear figuras.
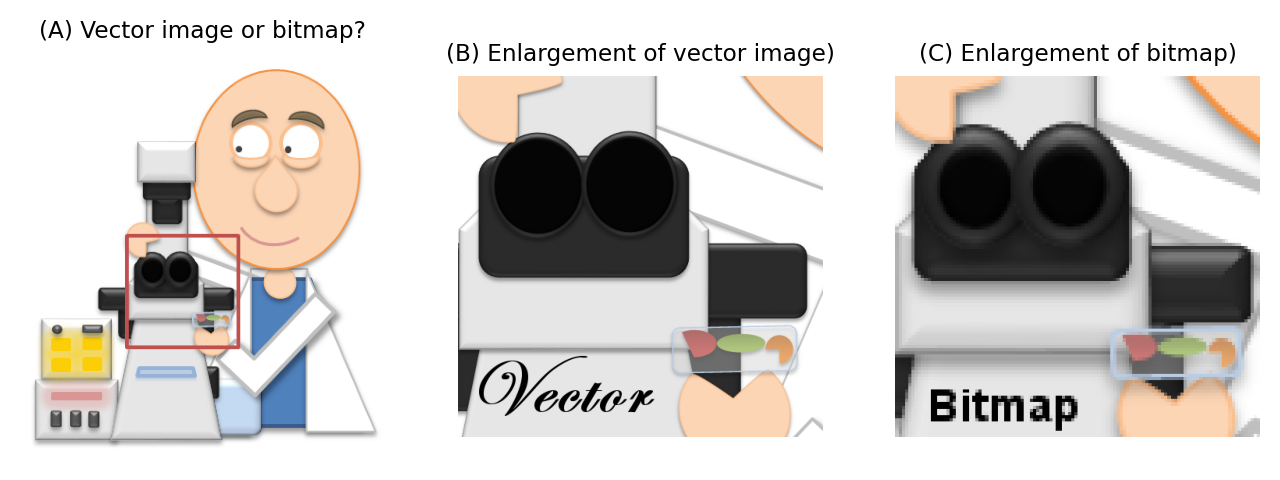
Figura 55 Cuando se ve desde lejos, puede resultar difícil saber si una imagen es un vector o un mapa de bits (A) porque a veces pueden parecer idénticas (aunque una fotografía o una micrografía siempre será un mapa de bits). Sin embargo, cuando se amplía, una imagen vectorial permanecerá nítida (B), mientras que un mapa de bits no (C).#
Imágenes piramidales#
Finalmente, terminamos con unas palabras sobre las imágenes piramidales: un tipo de imágenes cada vez más comunes.
Las bioimágenes modernas pueden ser enormes. No es raro que una sola imagen contenga muchos gigabytes de datos de píxeles, lo que hace que sea imposible abrir la imagen completa de una sola vez.
Sin embargo, para visualización o análisis a menudo no necesitamos todos los píxeles a la vez. Por ejemplo, cuando vemos una imagen, sólo necesitamos acceder a los píxeles que están visibles en la pantalla en cualquier momento, con el aumento con el que se están viendo.
Los archivos de imágenes piramidales ayudan a superar esto mediante dos trucos:
Almacenan la imagen como fragmentos separados (a menudo llamados «mosaicos», si son 2D)
Almacenan la misma imagen en diferentes resoluciones en el mismo archivo

Figura 56 Diagrama esquemático de una imagen piramidal. La imagen en sí (izquierda) se divide en partes y se almacena en múltiples resoluciones. Los fragmentos necesarios para mostrar el campo de visión actual (arriba a la derecha) están resaltados en amarillo. La imagen de diapositiva completa original aquí es del gran desafío CAMELYON.#
El software diseñado para manejar imágenes piramidales puede luego sumergirse en el archivo de imagen y leer sólo la parte de la imagen que se necesita en ese momento. A menudo, esto es sólo una pequeña proporción de todo el conjunto de datos.
Las imágenes piramidales son especialmente habituales en patología, aunque empiezan a utilizarse más para otras aplicaciones. QuPath es un software de código abierto diseñado específicamente para manejar imágenes piramidales de manera eficiente (y resulta que también es el software que escribí y mantuve, porque no pude hacer el análisis con otras herramientas de código abierto en ese momento). Aunque QuPath puede hacer muchas cosas por sí solo, también se puede utilizar con ImageJ.